Это русский перевод* страницы
cluster.cis.drexel.edu/~cchen/papers/2008/jadt2008.pdf
Автора
Чаомей Чена
Профессора информатики
Колледжа вычислительной техники и информатики
Университет Дрекселя
Выявление тематических вариаций в исследованиях SDSS
Чаомей Чен 1 , Фиделия Ибекве-Сан-Хуан 1,3 , Эрик Сан-Хуан 2 , Майкл С. Вогли 4
- 1.iSchool, Университет Дрекселя – 3 141 Chestnut Street – Филадельфия, Пенсильвания 19104 – США
- 2.LIA, Université d’Avignon – 339, Chemin des Meinajaries
84 911 Авиньон CEDEX 09, Франция {[email protected]}
- 3.ELICO – Université de Lyon3, 69 008 Lyon. {[email protected]}
- 4.Физический факультет Университета Дрекселя – 3 141 Chestnut Street – Philadephia,
PA 19104 – США. {[email protected]}
Аннотация
Научный проект «Sloan Digital Sky Survey» (SDSS) является актуальным элементом грандиозного проекта наблюдения небесных объектов для астрономического сообщества. С макроскопической точки зрения вопрос
фундаментальной позиции: знание того, как астрономические данные наблюдаются и публикуются проект SDSS влияет на эволюцию научных исследований в астрономии. Комментарии исследователей.
Используют ли они наблюдаемые данные для ориентирования в своих исследованиях? Мы предлагаем комплексный подход к исследованию текстов, сочетающих статистические и символические методы, чтобы продемонстрировать, как этот подход и его комбинация является ответом на вопросы эволюции астрономических исследований.
Ключевые слова: интеллектуальный анализ текста, обнаружение тем, визуализация информации, эволюция тем.
- Введение
Обнаружение и отслеживание важных тем в огромном объеме данных является фундаментальным вызов для нескольких задач интеллектуального анализа текста (Berry 2004), включая наблюдение за наукой и технологиями (Schiffrin & Börner 2004; Ibekwe-SanJuan & SanJuan 2004) и нанесение на карту научных границ (Чен, 2006). Как главный астрономический обзор нашего времени, Sloan Digital Sky Survey (SDSS) собрал обширную и быстро растущую литературу о своих открытиях.
Обзор SDSS направлен на получение подробных оптических изображений, покрывающих более четверти неба,
и трехмерной карты около миллиона галактик и квазаров.
В этом исследовании мы применяем две разные системы интеллектуального анализа текста для выявления тематических тенденций в статьях со ссылкой на выпуски данных SDSS, а именно CiteSpace II (Chen 2003, 2006) и TermWatch (SanJuan И Ибекве-Сан-Хуан 2004, 2006). Обе системы предназначены для кластеризации информационных единиц, например, таких как авторы; автор назначил ключевые слова, словосочетания существительных на нескольких уровнях детализации. Эти системы также включают визуальный аналитический компонент, чтобы пользователь мог исследовать и усваивать сложные отношения между информационными единицами. В этом исследовании CiteSpace используется для того, что бы извлекать, выбирать и визуализировать ассоциации между парами функций документа. Этот анализ графов ассоциаций подкрепляются затем обобщением бинарных ассоциаций с частыми элементами набора данных для каждого отдельного выпуска данных SDSS на условиях, извлеченных TermWatch. Наконец, мы используем декомпозицию атомного графа, что реализована в TermWatch для выбора и визуализации часто используемых элементов наборов данных.
Наш массив состоит из 1293 библиографических записей найденных публикаций, связанных с SDSS из базы данных «ISI Web of knowledge» (Thomson Scientific). Эти записи содержат обычные библиографические поля, такие как заголовок, автор, аннотация, ключевые слова, принадлежность и дата. Поскольку наша цель – выделить влияние отдельного выпуска данных SDSS в дополнение к анализу всего массива. Весь набор данных был разделен на несколько подмножеств соответствующих индивидуальному выпуску данных SDSS. Каждый выпуск данных описывается основным техническим документом. В этом исследовании мы анализируем первые 6 выпусков данных. Последний DR6, выпущенный в 2007 г. был опущен.
Остальная часть статьи построена следующим образом: в разделах §2 и §3 представлен обзор Системы CiteSpace и TermWatch соответственно с особым упором на используемые функции для добычи массива SDSS. В разделе 4 анализируются результаты, а в разделе 5 делаются некоторые выводы из эксперимента.
- Построение ассоциативных графов с помощью CiteSpace
CiteSpace предназначен для визуализации и анализа возникающих тенденций и макроскопических изменения научной области через ее научную литературу (Chen 2004; Chen 2006). В общая конструкция изображена на следующей диаграмме (Рис.1). Обычно CiteSpace занимает набор библиографических записей в качестве входных данных и генерирует интерактивные визуализации, которые помогают пользователям исследовать и идентифицировать макроскопические модели. Технические подробности см. в (Chen, 2004 и Chen, 2006). CiteSpace сначала делит входящие записи на серию временных отрезков. Данные обрабатывается в каждом временном интервале и таким образом создаётся сеть. Сеть состоит из двух типов субъектов, а именно узлов и ссылок. CiteSpace поддерживает авторов, статьи, журналы, учреждения и узлы страны. Он также поддерживает фразы, извлечённые из заголовков и аннотаций статей. Мы будем особенно акцентировать внимание на роли фраз в этой статье. CiteSpace поддерживает типы ссылок, которые могут быть производными от заданных типов узлов. Например, ссылки между фразой и статьей определяются как реферальные ссылки, тогда как совместные ссылки являются производными от соавторства. Однажды такие сети в отдельных временных срезах будут объединены, чтобы сформировать глобальная сеть. В глобальной сети доступен ряд фильтров, чтобы можно было рендерить сеть с более конкретным фокусом. Например, меры центральности промежуточности (Freeman, 1973) узлов используются для определения ключевых точек интеллектуальных изменений. В этой статье мы сосредоточимся на нескольких статистических фильтрах, которые имеют отношение к поставленной задаче.
Функции CiteSpace, использованные в этом исследовании, включают:
- i) обнаружение всплесков (Kleinberg 1999),
- ii) выбора признаков, основанный на тестах логарифмической вероятности статистической ассоциации, и
iii) теоретико-информационные индексы (Chen 2008). Все три функции применяются к многословным фразам, извлечённых из массива литературы SDSS. Они будут подробно описаны в разделе результатов.
(§4).
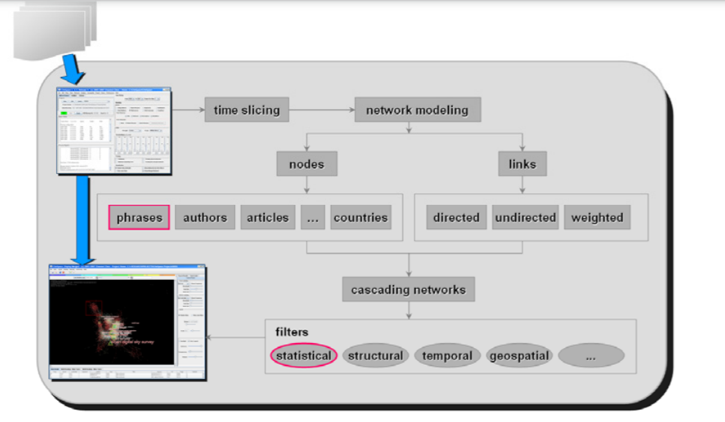
Рисунок 2. Схема информационных потоков CiteSpace.
- Извлечение частых наборов элементов и атомных графов с помощью
Во-первых, мы даём общий обзор TermWatch перед более подробным описанием конкретных функций, использованных в этом эксперименте.
TermWatch (SanJuan & Ibekwe-SanJuan 2004, 2006) отображает темы исследования на уровне терминов. Он полагается на поверхностную лингвистическую и терминологическую информацию для извлечения терминов и построения график терминологических отношений между ними. Недавно мы добавили новый интеллектуальный анализ текста такие функции, как частый поиск наборов элементов на основе «пакета arules R» и разложения атомного графа.
Эти недавние дополнения к системе являются основными функциями, используемыми в текущем эксперименте. Частые наборы элементов обобщают идею ассоциаций. Они могут указать n – простых отношений между терминами, тогда как ассоциации порождают бинарные отношения. Сначала мы используем CiteSpace, чтобы получить макроскопическое представление, основанное на бинарных отношениях концептов, а затем использовать извлечение терминов TermWatch и анализ частых наборов элементов для выявления конкретных выпусков данных темы. На рис.2 внизу показан конвейер различных уровней анализа текста в TermWatch.
3.1. Извлечение терминов и выбор признаков
Обычно в процедуре извлечения терминов TermWatch термины из нескольких слов (без ограничения длинны) извлекаются на основе их морфо-синтаксических свойств. Используются все извлечённые термины в дальнейшей обработке без учёта возникновения. Однако в этом эксперименте акцент был сделан не на редких обозначениях, поэтому нам пришлось разработать индекс выбора функций, который исключить редкие термины. Сначала мы выполнили извлечение терминов с использованием морфо-синтаксических паттернов и исключаем все термины, встречающиеся только один раз. Затем мы вычислили средне геометрическую инерцию, вызванная двумя функциями tf.idf. Одна основана на появлении всего термина, другая основана на вхождении слов термина с использованием функции сопоставления MYSQL и документа нормализации длины. Верхние термины должны быть частыми, чтобы относиться к подмножеству документов, не будучи слишком частыми или равномерно распределенными по массиву данных.
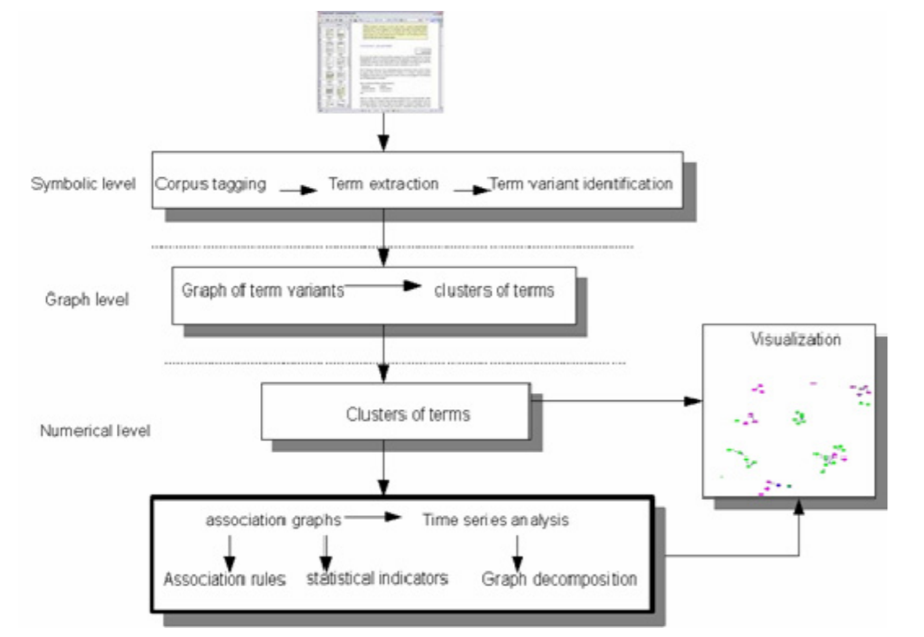
Рисунок 3. Конвейерное представление функций анализа текста в TermWatch.
Таким образом, выражения кандидатов ранжируются в соответствии с оценкой G (t), которая рассчитывается следующим образом:
путь:
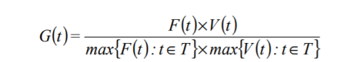
где:
![]()
а также
F (t) отдает предпочтение названному значению, тогда как критерий V (t) отдает предпочтение более общим терминам, таким как технические подходы или методы.
![]()
В табл. 1 ниже приведены первые 20 терминов, ранжированных G-Mean.
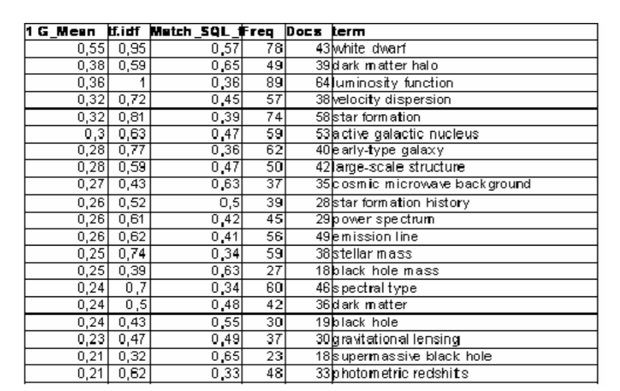
Таблица 1. Первые 20 терминов, ранжированных по индексу G_mean.
3.2. Частотные наборы предметов
Теперь мы работаем над соотношением документов и их условий. Чтобы прояснить связи между частым поиском наборов элементов и графами ассоциаций, мы увидим любое множество D документы , как гипер-граф H . Каждый документ представлен гипервершиной. Каждый из элементов текстовых данных, например термины, представлены подмножеством документов разделяющих этот конкретный атрибут. Эти подмножества образуют гипер-ребра этого гиперграфа.
Формальные концепции соответствуют минимальным трансверсалиям гиперграфа. Действительно, для любого подмножества S из гипервершин, обозначим через T (S) множество гиперребер h таких, что h ∩ S ≠ Ø . S , как говорят, минимальная трансверсаль, если для любого s из S T (S – s) ≠ T (S) .Теперь рассмотрим соотношение R
Между множеством документов D имножеством терминов K, определенных как (d, t) ∈ R, тогда и только тогда, когда документ d содержит термин t (t ∈ d) .
Для набора ключевых слов V обозначим через Ext (V) набор документов, проиндексированных всеми терминами в V . Внешн (V) , называется формальное расширение V . Наоборот, для набора документов U пусть Обозначим через Int (U) множество терминов индексирования все документы в U . Int (U) называется формальной интенцией из U . Таким образом , формальная концепция пара ( U, V ) таким образом, что внешн (V) = U и Int (U) = V . Это несложно проверить, что если S – минимальная трансверсаль, то (S, T (S)) – формальная концепция. Формальные концепции частично упорядочены включением в их расширения. В результате решетка. Подмножество ключевых слов или терминов называется закрытым, если это является смыслом формального понятие или, что то же самое, минимальная трансверсаль гиперграфа.
В зависимости от типа информации, которую пользователь хочет анализировать, карты знаний могут быть
производные образуют части H в виде графов пересечений, которые мы также будем называть ассоциативными графами и обозначим их через G k (V, E), где V – множество вершин (узлов), E – множество ненаправленных ребер (ссылки), а k – целое число. Вершины в V представляют выбранные гиперребра, в то время как ребро рисуется между двумя вершинами (w 1 , w 2 ), если они содержат не менее k элементов в своих пересечениях.
Для малых значений k ожидается , что G k (V, E) будет Графом Малого Мира (SWG). Граф называется принадлежащим SWG, когда он одновременно показывает как малый диаметр, так и высокую степень кластеризации (т.е. высокая плотность ребер в окрестности каждой вершины). Согласно (Ferrer & Sole 2001), длина пути L (p) и коэффициент кластеризации C (p) являются двумя структурными измерения, характеризующие SWG. Обычный подход к визуализации SWG состоит в вычислении разложения на компоненты с высокой степенью связи и предложение пользователю абстрактный вид сети для начала (Auber et al. 2003).
Мы принимаем аналогичный подход, за исключением того, что вычисляем перекрывающиеся атомы (Берри и др., 2004) вместо непересекающихся связных компонентов. Атомы графа могут быть определены на основе понятия (а, б) -кликовых разделителей. Это полные подграфы (все вершины связаны) такие, что существуют две вершины a, b, не входящие в разделитель, и такой, что любой путь от a до b обязательно содержит хотя бы один элемент в разделителе.
Мы будем говорить, что граф неотделим, если нет подграфа, являющегося полным разделителем. Мы будем называть атомом графа любой неотделимый связный максимальный подграф. По По определению, атом A группы G k содержит хотя бы один полный разделитель S группы G k . Однако S не сепаратор A . Атомы перекрываются, если они содержат один и тот же разделитель Gk . Разложение группы G k в атомах единственна и может быть разложена за O (| V | × | E |).
В наших экспериментах мы наблюдали, что графики вида G k (V, E) для k от 1 до 3 имеют центральный атом с длинными циклами, который включает почти 50% вершин и множество периферические атомы небольшого размера, почти хордовые (круги имеют менее трех элементов).
3.3. Графы атома
Для визуализации атомов и их взаимодействий на карте мы определяем исключительно ценностный граф на основе структуры G k (V, E) . Каждый атом A помечен вершиной w 1, имеющей наивысшую степень, определяется как число ребер , соединяющее ж 1 в другую вершину ш 2 в А . Атомы, имеющие одинаковые ярлыки объединяются.
Значимый граф атомов, который мы обозначим G k (At) = (V At , E At , a At ) , определяется следующим образом.
Вершиной G k (At) являются пары вида (k, l), где k – вершина G k, а l – метка атом, содержащий k . Ребро e = (w 1 , w 2 ) определяется между двумя вершинами w 1 = ( k 1 , l 1 ) и w 2 = ( k 2 , l 2 ), если произойдет одно из следующих событий:
– l 1 = l 2 и ( k 1 , k 2 ) является ребром G k . В этом случае значение s At ребра e устанавливается равным 1.
– k 1 = k 2 и существует кликовый разделитель S в G k, который отделяет атом l 1 от атома атом l 2 . В этом случае a At (w1, w2) устанавливается равным отношению количества элементов в S и общее количество элементов в атомах l 1 и l 2 .
Первый случай соответствует ребрам в атомах. Чтобы гарантировать, что связанные вершины не будут разделены любой процедурой кластеризации, мы устанавливаем значение таких ребер равным 1, максимально.
Второй случай касается ребер, связывающих копии G k вершин в разных атомах. Это оценочный график можно отобразить, как описано ниже.
Наконец, с помощью интерактивного интерфейса AiSee (http://www.aisee.com) и его оптимизированного двухпозиционного масштабированного силового направленного макета, мы получаем двухуровневый доступ к сети ключевых слов. Идея заключается в улучшении визуализации графиков, полученных TermWatch, путем определения основной сеть данных, которые образуют неразрывный подграф и отличают его от других спутников или периферийных исследовательских тем.
В качестве входных данных AiSee требуется файл на языке описания графов (GDL). Наш генератор GDL использует ширину грани, чтобы визуализировать прочность ссылки. Затем кластеры представлены овалами, размер которых зависит от количества кластеризованных вершин. Наконец, кластеры можно развернуть в виде свернутой формы для визуализации переходов к другим кластерам.
- Результаты
Несколько карт были получены из массива SDSS как в макроскопическом виде высокого уровня в целом массиве (сети совместного цитирования авторов) и на микроскопическом уровне. По пространственным причинам, мы сосредоточимся на временной эволюции тем в выпусках данных (DR). Кроме того, этот аспект является важным аспектом проекта обзора литературы SDSS.
4.1. Сеть ассоциаций
CiteSpace рассчитал силу ассоциаций между извлеченными терминами, используя логарифмический тест отношения правдоподобия. Основная мотивация использования тестов логарифмического отношения правдоподобия связана с его сильными сторонами в моделировании поведения низкочастотных текстовых единиц. Связи между терминами выбираются, если они статистически значимы на уровне p = 0,01. На рис. 3 показана сетевая визуализация выбранных таким образом терминов и их ассоциаций.
Более светлые оттенки обозначают термины, обнаруженные в более раннем периоде массива. Более темные оттенки обозначают термины, найденные в более позднем периоде массива. Например, такие термины, как « звезда формирования истории, рентгеновская группа и групповой член”образуют небольшой кластер светлого цвета.
Напротив, « источник рентгеновского излучения и верхнее скорпиу » связаны в более позднем периоде тела.
4.2. Условия всплеска
Согласно Кляйнбергу (1999), пакетные выражения – это текстовые единицы, которые появляются чаще, чем ожидается в определенный период времени. Следовательно, их обнаружение может указывать на всплеск интереса к теме в это время. CiteSapce использовался для обнаружения условий пакета во всех наборах данных DR. Соответствующее изображение показано на рис.4. Мы аннотировали дату выпуска конкретных данных. Ранний выпуск данных (EDR) состоялся в июне 2001 года и, похоже, был сосредоточен на « визуализации данных », популярный термин в тот период. Более поздние исследования начали относиться к EDR, поэтому всплеск употребления термина « ранняя публикация данных » обнаружился в следующем 2002 году. Первые данные релиз (DR1) был выпущен в начале 2003 года с появлением таких терминов, как « диапазон красного смещения, темная материя ». Ссылки на DR1 со стороны других исследователей стали значительными в 2004 году, отсюда и рост термина « SDSS-DR1 » в этом году вместе с другими сопутствующими терминами, такими как пространственное распределение » и « распределение цвета ». Второй выпуск данных (DR2) стал доступен в
2004 г., а ссылка на « DR2 » стала статистически значимой в 2005 г. с термином « Звездная металличность» . Влияние DR3 с точки зрения связанных условий всплеска, по-видимому, связано с спектром квазаров . DR4 обозначается следующими элементами пакета: « корреляционная функция, скоростная дисперсия, исследователь эволюции галактик ». Ссылка на DR4 стала важной в DR5 наряду с другими элементами всплеска, такими как лямбда-лямбда, спектры квазаров .

Рис. 3. Сеть ключевых слов, основанная на силе связи, измеренной логарифмической вероятностью соотношения. Ключевые слова с более светлыми цветами появились в первые годы. Используется весь набор данных SDSS.
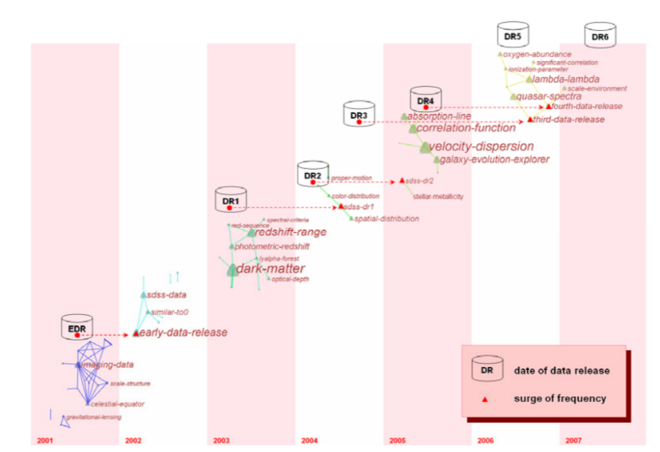
Рисунок 4. Представление часового пояса, созданное CiteSpace, показывающее пакеты всплеска из литературы SDSS.
набор данных (1993 г. – октябрь 2007 г.). Изображение снабжено аннотацией с датой каждого выпуска данных SDSS.
4.3. Анализ частых наборов элементов в выпусках данных
Чтобы получить подробное представление об эволюции темы в различных выпусках данных, мы вычислили частые наборы элементов и атомные графы на основе терминов, извлечённых TermWatch по всему массиву, но распределенных по статьям, относящимся к различным DR. Из-за недостатка места мы ограничиваем наши результаты правилами и атомными графами, полученными на записях, цитирующих DR1 и DR2. На графиках ниже показаны правила ассоциации, полученные из терминов DR1.
4.3.1. Правила ассоциации и атомные графы на основе Data Release 1
Для DR1 10 наиболее часто используемых правил ассоциации обсуждаются ниже. Мы представляем их в виде правил ассоциации, поскольку в этих часто встречающихся наборах элементов факт появления третьего или пятого элемента позволяет сделать вывод о других. Таким образом, каждое из следующих правил соответствует частому набору элементов, состоящему из всех терминов правила (часть, что слева направо ).
{экваториальная полоса, подвыборки с ограниченным объемом} => {экваториальная плоскость}
{экваториальная плоскость, подвыборки ограниченного объема} => {экваториальная полоса}
{экваториальная полоса, подвыборки ограниченного объема} => {распределение галактик}
{модель атмосферы, белый карлик} => {первый выпуск данных}
{экваториальная полоса, подвыборки ограниченного объема} => {распределение галактик}
{подвыборки с ограниченным объемом} => {экваториальная плоскость}
{большое количество, каталог собственных движений} => {USNO-B}
Рисунок 5. 10 правил ассоциации, относящихся к DR1.
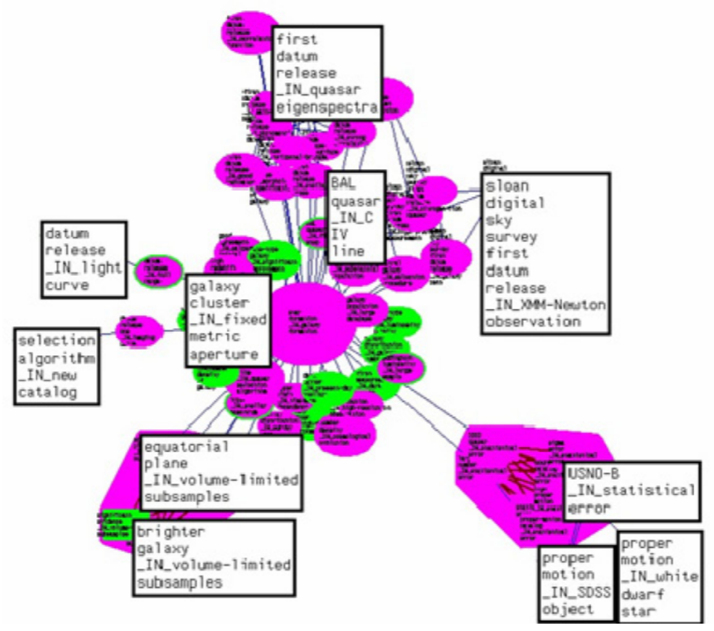
Рисунок 6. Атомный граф терминов в рефератах, относящихся к DR1. Атомы заключенные в цвета соответствуют правилам ассоциации большей поддержки.
На рис.6 показан атомный граф на DR1. График атома сосредоточен на « формировании галактики», что означает, что термин «формирование галактики» – это метка скопления, а термин «звездное формирование» является членом кластера, который наиболее тесно связан с терминами за пределами кластера . Однако атомы, которые объясняют наиболее частые правила ассоциации, являются маргинальными, как это показано на рисунке ниже. Есть два атома, которые окружены « ограниченным объёмом подвыборки » и « статистическая ошибка » (внизу слева на графике). Как и ожидалось, атомы уважают правила ассоциации, и большинство из них можно сопоставить с формальной концепцией.
4.3.2. Правила ассоциации и атомные графы на основе Data Release 2
Для второго выпуска данных мы получили пять наборов элементов с высокой поддержкой (18%).
{локальная вселенная, звездная масса} => {галактика, образующая звезды}
{локальная вселенная, галактика звездообразования} => {звездная масса}
{локальная вселенная} => {звездная масса}
{локальная вселенная} => {галактика, образующая звезды}
Рисунок 7. Топ-5 правил ассоциации с высокой поддержкой DR2.
График атома сосредоточен на звездообразующей галактике, которая заключена в более крупный атом.
меченое активное ядро.
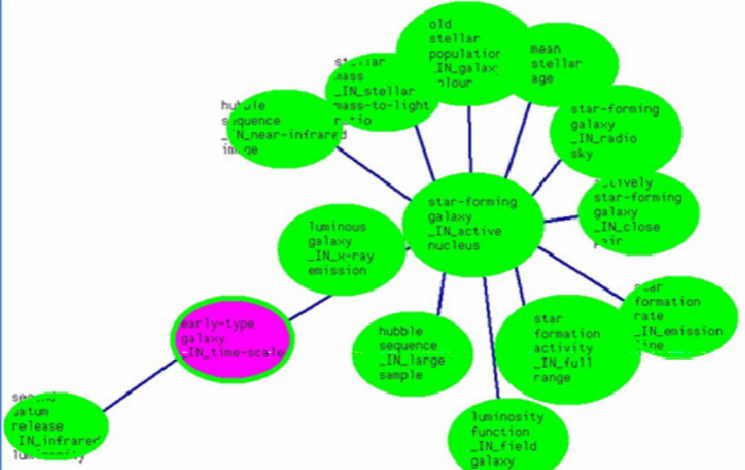
Рисунок 8. Граф атома, полученный на DR2.
Обратите внимание, что самый большой атом «полного диапазона» связан с активным ядром центрального атома.
через термин « галактика звездообразования». Атом « полного диапазона » содержит все термины, входящие в шесть правил ассоциации, как показано на рис. 9 ниже, где этот атом развернут.
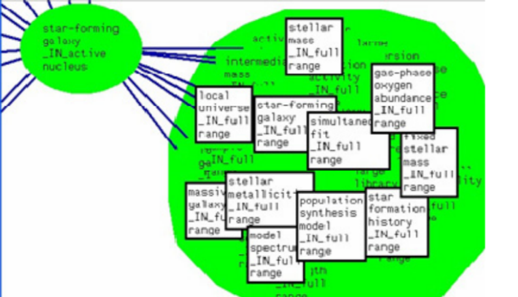
Рисунок 9. Развернутая версия самого центрального атома «полного диапазона» для DR2.
4.3.3. Пересмотр общего графа ассоциаций
За каждой ассоциацией на графике на рис.3 можно найти атом терминов, указывающих на из потенциально частых наборов предметов. В качестве примера атомный граф в DR2 даёт контекст ассоциации между « звездообразованием » и « галактиками средних масс ». Атом показывает что все термины почти систематически встречаются вместе. Как показано на рис.3, с точки зрения интенсивности цвета этих вершин, эта ассоциация кажется значительной в последних выпусках. Однако мы можем видеть, что эта связь присутствовала со времён DR2 и привела к самому большому атом извлечён из этого выпуска, хотя этот атом не является центральным. В следующих данных выпуска, этот атом встречается не чаще, чем самый большой, но занимает более центральное положение в атомном графе.
- Обсуждение
Всесторонний анализ представленных здесь результатов выходит за рамки данной конференции и требует знания предметной области. Мы все ещё продолжаем исследование влияния различные релизы данных об исследованиях SDSS. Этот анализ не может быть завершён здесь из-за нехватки места. Однако мы ожидаем некоторых предварительных результатов, которые перспективны в этом направлении. Также мы постарались уточнить отношения между ассоциацией анализа графов и добычи частых наборов элементов на основе атомных графов.
Чтобы перейти к систематической оценке результатов комбинации этих методов, мы реализуем систему автоматического составления резюме, которая поддерживает ассоциацию или атом. Это позволит учёным управлять двумя компонентами формальной концепции легко, а именно намерение, которое соответствует частому набору элементов и расширение, сделанное из документов, которые образуют поддержку часто встречающегося набора позиций.
Благодарности
Работа, представленная здесь, частично поддержана Национальным научным фондом в рамках гранта.
№ 0612129.
Ссылки
Берри А., Каба Б., Надиф М., Сан-Хуан Э., Сигайрет А. (2004). Classification et désarticulation de
графики de termes. В JADT 2004. Лувен-ля-Нев, Бельгия, стр. 160-170.
Обер Д., Чирикота Ю., Журдан Ф., Меланкон Г. (2003). Мультимасштабная визуализация маленького мира
сети. В симпозиуме IEEE по визуализации информации, IEEE Computer Society , стр. 75-81.
Берри М.В. (ред.). (2004). Обзор Text Mining. Кластеризация, классификация и поиск. Спрингер,
Н-Й, 244.
Чен С. (2008). Теоретико-информационный взгляд на визуальную аналитику. Компьютерная графика IEEE и
Приложения . (Январь / февраль 2008 г.).
Чен С. (2006). CiteSpace II: обнаружение и визуализация новых тенденций и переходных закономерностей в
научная литература. Журнал Американского общества информационных наук и технологий ,
57 (3), стр. 359-377.
Чен С. (2004). В поисках интеллектуальных поворотных моментов: область прогрессивных знаний
Визуализация. В трудах Natl. Акад. Sci. USA , 101 (Suppl.), Pp. 5303-5310.
Феррер-и-Канчо Р., Sole RV (2001). Маленький мир человеческого языка. В трудах
Лондонское королевское общество . Series B, Biological Sciences 268 (1482) , стр. 2261-2265.
Гамон М. (2006). Графическое представление текста для обнаружения новинок. В трудах
Семинар по TextGraphs на HLT-NAACL 2006, стр. 17-24.
Гантер Б., Вилле (1998). Формальный анализ понятий: математические основы . Спрингер-Верлаг,
Берлин.
Ибекве-Сан-Хуан Ф., Сан-Хуан Э. (2004). Анализ текстовых данных с помощью кластеризации вариантов терминов:
Система Termwatch. В материалах конференции «Recherche d’Information assistée par.
ordinateur », (РИАО-04). Авиньон, стр. 487-503.
Сан-Хуан Э. и Ибекве-Сан-Хуан Ф. (2006). Анализ текста без контекста документа. Информация
Обработка и управление . Эльзевир, 42 (6), стр. 1532-1552.
Шиффрин Р., Бёрнер К. (2004). Отображение областей знаний. Издание Национальной академии Наука (PNAS), 101 (1), стр. 5183-5185.
Чаомей Чэнь в биографических набросках

ORCID: orcid.org/0000-0001-8584-1041
ResearcherID : A-1252-2007
Идентификатор автора в Scopus: 7501950297
Профиль петли: 262902
Домашняя страница: http://www.pages.drexel.edu/~cc345
LinkedIn: http://www.linkedin.com/in/chaomeichen
ResearchGate: www.researchgate.net/profile/Chaomei_Chen/
Академия Google: http://scholar.google.com/citations?user=IjN4HSRsdakC&hl=en
Microsoft Academic: https://academic.microsoft.com/#/profile/ChaomeiChen
CiteSpace: https://sourceforge.net/p/citespace/
Доктор Чаомей Чен – профессор информатики в колледже вычислительной техники и информатики Дрексельского университета в США. Он является главным редактором журнала « Визуализация информации» (1473-8716; 1473-8724) и главным редактором журнала Frontiers in Research Metrics and Analytics. (2504-0537). Он является автором серии книг по визуализации эволюции научного знания, а также стратегий и методов критического мышления, творчества и открытий, в том числе «Представление научных знаний: роль неопределенности» (Springer, 2017), «Соответствие информации: количественные данные». Assessments of Critical Information (Wiley, 2014), Turning Points: The Nature of Creativity (Springer, 2011), Information Visualization: Beyond the Horizon (Springer, 2004, 2006), Mapping Scientific Frontiers: The Quest for Knowledge Visualization (Springer 2003, 2013). ). Он является создателем широко используемой программы визуальной аналитики CiteSpace для визуализации и анализа структурных и временных закономерностей в научной литературе.
Д-р Чен занимается исследованиями и научным опытом в области визуального аналитического мышления и оценки важной информации, касающейся структуры и динамики сложных адаптивных систем. Его работа сосредоточена на выявлении новых тенденций и потенциально преобразующих изменений в развитии науки и технологий, особенно с помощью вычислительных и визуальных аналитических подходов. Доктор Чен постоянно публиковал научные работы. Его работы были процитированы в Google Scholar более 18 000 раз. Его исследование финансируется Национальным научным фондом (NSF) и спонсируется промышленными спонсорами, такими как Elsevier, IMS Health, Lockheed Martin и Pfizer. Его предыдущие исследования финансировались Европейской комиссией, Советом по исследованиям в области инженерных и физических наук (Великобритания) и Библиотечно-информационной комиссией (Великобритания). Он получил степень бакалавра наук, кандидат математических наук (Университет Нанкай, Китай), степень магистра наук. в области вычислений (Оксфордский университет, Великобритания) и докторскую степень. Кандидат компьютерных наук (Ливерпульский университет, Великобритания).
Одна из последних книг Д-ра Чена на Амазоне:

![]() © 2020. This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License (https://creativecommons.org/licenses/by-sa/4.0/)**.
© 2020. This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License (https://creativecommons.org/licenses/by-sa/4.0/)**.
*Уполномоченный русский перевод
Публикация 28 августа 2020
Текущая версия:
https://thesisowl.com/2020-09-25-identifying-thematic-variations-in-sdss-research/
Последняя версия:
https://thesisowl.com/2020-09-28-identifying-thematic-variations-in-sdss-research/
Оригинальная версия (на английском языке):
cluster.cis.drexel.edu/~cchen/papers/2008/jadt2008.pdf
Организатор перевода:
ThesisOwl,
Украина, Киев, 01014,
бул. Леси Украинки, 26, 3 этаж
Сайт: https://thesisowl.com
Редакторская правка перевода
EuroWay
Украина, Киев, 03035, Соломенская площадь, 2, 6 этаж
Координатор перевода
Девид Диаз (e-mail: [email protected])
Настоящий документ является авторизованным переводом документа Массачусетского университета г.Амхерст(https://people.umass.edu ). Публикация этого перевода производится в соответствии с этапами, описанными в правилах подготовки авторизованных переводов (Policy for W3C Authorized Translations). Во всех спорных случаях основной считается оригинальная версия данного документа на английском языке.
**Creative Commons
Мы публикуем этот перевод и звуковой файл, его воспроизводящий для людей с проблемами зрения, как производные документы по лицензии Creative Commons. Вы можете использовать наши материалы и развивать работу в некоммерческих или коммерческих целях при условии, что вы выполните оригинальную публикацию и включите обратную ссылку на thesisowl.com (thesisowl.com/2020-09-28-identifying-thematic-variations-in-sdss-research/).
Это официальная лицензия Creative Commons:
Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)
Вы можете:
Share – копировать и распространять материал на любом носителе и любом формате.
Adapt – ремикшировать, преобразовывать и дополнять материал для любых целей, даже в коммерческих целях.
На следующих условиях:
Attribution – вы должны указать соответствующую отметку, предоставить ссылку на лицензию и указать, были ли внесены изменения. Вы можете сделать это любым разумным способом, но не любым способом, который предполагает, что лицензиар одобряет вас или ваше использование.
ShareAlike – если вы уменьшаете, трансформируете или дополняете материал, вы должны распространять свои материалы по той же лицензии, что и оригинал.
Детали лицензии:
https://creativecommons.org/licenses/by-sa/4.0/
КАК СОСЛАТЬСЯ НА ЭТУ ПУБЛИКАЦИЮ (HOW TO CITE THIS PUBLICATION):
Якорь (ancor) – ThesisOwl
URL – https://thesisowl.com/2020-09-28-identifying-thematic-variations-in-sdss-research/
Пример (example) – ThesisOwl