Int. J. Man-Machine Studies (1983) 18, 199-214
Користувачами є приватні особи:
– індивідуалізація моделей користувачів
ЕЛЕЙН РІЧ
Департамент комп’ютерних наук Техаського університету в Остіні, Остін, штат Техас 78712, США
(Отримано 13 травня 1981 р.)
Давно визнано, що для того, щоб побудувати гарну систему, в якій людина і машина співпрацюють виконуючи завдання, важливо враховувати деякі суттєві характеристики людей. Ці характеристики
використовуються для побудови якоїсь “моделі користувача”. Традиційно побудована модель є моделлю канонічного (або типового) користувача. Але часто окремі користувачі настільки різняться, що модель канонічного користувача є недостатньою. Натомість, необхідні моделі окремих користувачів. У цій статті представлено кілька прикладів ситуацій, в яких людино- користувацькі моделі важливі. У ньому також представлені деякі прийоми, що можливо дозволяють побудувати та використовувати такі моделі. Всі ці методи відображають бажання покласти більшу частину тягаря побудови моделей на системи, а не на користувача. Це призводить до розробки моделей, які представляють собою колекції добрих здогадок користувача. Таким чином, необхідні якісь імовірнісні міркування. І оскільки моделі використовуються для керівництва основної системи, вони також повинні контролюватися та оновлюватися, як пропонується взаємодією між користувачем та системою. Обговорюється продуктивність такої системи, яка використовує деякі з цих методів.
1. Вступ
Давно визнано, що для того, щоб побудувати хорошу систему, в якій людина і машина співпрацюють
Виконуючи завдання, важливо враховувати деякі суттєві характеристики людей. Тоді система може бути
покликаний скористатися цими характеристиками, а не боротися проти них.
Традиційно це робилося шляхом збору даних про виконання середньостатистичної людини різними завданнями в різних середовищах. Наприклад, закон Фіттса (Fitts & Peterson, 1964) говорить, що часу потрібно людині переміщення предмета в руці до конкретного цільового положення пропорційне log 2 (2A / w), де A – відстань переміщений і w – ширина цілі. Цей результат свідчить про те, як швидко людина може оперувати
Машину можна збільшити, збільшивши розмір цілей (таких як кнопки та перемикачі), які оператор повинен досягти. Як ще один приклад цього класу робіт розглянемо великий обсяг даних про взаємозв’язок між
розміром літер та їх розбірливістю (Smith, 1979). Ці результати важливі для дизайну не тільки найрізноманітніших машин, а також інших артефактів, таких як дорожні знаки.
Основна слабкість цих досліджень полягає в тому, що вони роблять припущення, що люди, які беруть участь у цьому, складають однорідний набір. Згідно з цим припущенням, цінностями, які визначені для характеристики «типової» людини, можуть бути
використовується для проектування системи, якою користуватимуться всі. Хоча в більшості випадків це правда, що принаймні для більшості людей, система краще пристосована до них, ніж була б без цих досліджень, але неправда, що така система, ймовірно, буде найкращою з усіх можливих. Набагато кращою буде система, в якій інтерфейс представлений кожній людині був би пристосований до ії власних характеристик, а не до характеристик якогось абстрактної “типової”
людини. Хоча в літературі про людські фактори обговорення індивідуальних відмінностей серед користувачів трапляються рідко, вони трапляються, тому що не зовсім відсутні. Наприклад, Hudgens & Billingsley (1978) стверджують, що стать є важливою змінною у людини як фактор дослідження. Інше дослідження, проведене Лоо (1978), обговорює індивідуальні відмінності у сприйнятті дорожніх знаків.
Однією з причин того, що такі дослідження були рідкісними, є те, що вони часто або занадто дорогі, або неможливі винайти фізичні пристрої – рівень гнучкості, який вони пропонують. Однак, коли ми починаємо бачити все більше і більше взаємодії людей з машинами, що опосередковуються комп’ютерами під програмним контролем, стає можливим забезпечити гнучкість, необхідна для справді персоналізованих систем.
Як простий приклад розглянемо ще раз питання розміру та читабельності літер. Якщо букви дисплея є такі, що виготовлені із використанням стандартного світлодіодного дисплея, вони будуть однакового розміру для всіх читачів. Але припустимо, букви є, що відображається на ЕЛТ, керованій комп’ютером. Тепер лінії можна проводити всюди, де це необхідно, щоб отримати широку різноманітність розмірів літер за запитом окремих користувачів.
Останнім часом дизайнери інтерфейсів користувач- комп’ютер почали зосереджувати увагу на потребах певних типів користувачів. Однією з груп, яку часто обговорювали, є клас “випадкових” користувачів, яких не можна очікувати щоб використовувати систему з великою мірою регулярності [див., наприклад, Codd (1974) та Cuff (1980)]. Тоді ця група повинна порівнювати з менш добре вивченими видами, звичайним, досвідченим користувачем. На жаль, буде мало систем що використовуються виключно людьми одного класу. І виявляється, що системні особливості, що полегшують життя для одного типу користувачів ускладнює це відповідно для іншого. Наприклад, одне дослідження ефективності користувачів-експертів при завданні редагування тексту (Card, Moran & Newell, 1980) передбачає, що кількість натискань клавіш, необхідних для виконання експлуатації повинно бути зведено до мінімуму. Ще одне дослідження людей, які тільки вчаться користуватися редактором (Ledgard, Whiteside, Singer
& Seymour, 1980) пропонує використовувати англійські команди з повними словами. Ці суперечливі вимоги
вказують на необхідність системи, яка може виглядати по-різному для різних користувачів.
Це пощастило, що комп’ютер забезпечує засоби для підвищення персоналізації, оскільки він також дає більше
потреби в цьому за рахунок збільшення кола завдань, для вирішення яких люди можуть сподіватися на прибуток, маючи справу з машинами. Завдання, які раніше виконувались людьми, такі як збір бажаної інформації з якоїсь бази даних, зараз робиться за допомогою комп’ютерів. Люди, які виконували ці завдання, змогли задовольнити різноманітні потреби інших людей, з якими вони мали справу. Якщо машини беруть на себе ці завдання і задовільно їх обробляють, вони теж будуть
повинні бути здатними пристосуватись до індивідуальних потреб. Для цього їм доведеться використовувати моделі
окремих користувачів, з якими вони стикаються. Це вимагатиме розширення традиційного поняття “модель користувача”.
В решті частини цієї статті ми розглянемо проблему моделювання користувачів конкретно в контексті комп’ютера і програмних систем, як через все частіше використання таких систем великими групами людей, так і через гнучкість, що властива таким системам, яка робить можливим ефективне моделювання.
2. Простір моделей користувачів
Термін “модель користувача” може бути використаний для опису найрізноманітніших знань про людей. Використання моделей користувачів охоплюють не менш широкий домен. Взаємозв’язки між цими різноманітними структурами можна побачити досить легко, якщо Всесвіт “моделей користувачів” характеризується як тривимірний простір. Розміри, кожен з яких буде обговорюються більш докладно нижче, є:
1.Одна модель одного, канонічного користувача проти колекції моделей окремих користувачів.
2.Моделі, явно вказані або конструктором системи, або самими користувачами, порівняно з моделями, виведеними системою на основі поведінки користувачів.
3.Моделі досить довгострокових характеристик користувачів, таких як сфери інтересів чи знань, порівняно з моделями відносно короткострокових характеристик користувача, такі як проблема, що користувач зараз намагається вирішити.
Є й інші суттєві відмінності між системами, що використовують ці різні типи користувацьких моделей, але вони випливають із цих основних відмінностей Системи з єдиною моделлю канонічного користувача можуть мати таку модель, що постійно вбудована в них самих, тоді як системи з моделями окремих користувачів повинні будувати модель на льоту, і тому повинні чітко вказати способи впливу моделі на ефективність загальної системи.
Системи, що витягують модель користувача з поведінки користувача, повинні серйозно боротися з проблемами неправильної або суперечливої інформації, що випливає з висновків, що призвели до моделі. Системи з явно вказаним користувачем інформацією, з іншого боку, може уникнути багатьох із цих питань. Системи, що займаються короткочасними знаннями, повинні успішно вирішувати проблему виявлення, коли щось змінюється, тоді як довгострокові системи можуть це робити витончено до цього питання. Але оскільки ці відмінності зводяться до трьох, описаних вище, на них не потрібно явно зосереджуватись.
Наступні три розділи коротко обговорюють, як можна вибрати найкраще положення в цьому тривимірному просторі.
2.1. КАНОНІЧНІ ПРОТИ ІНДИВІДУАЛЬНИХ МОДЕЛЕЙ
Цей вимір характеризує основну різницю між “класичною” роботою людських факторів та більш гнучкою моделлю, що необхідні для забезпечення індивідуалізованих інтерфейсів, що дозволяє програмне управління. Різноманітні комп’ютерні системи
були розроблені навколо канонічної моделі користувача. Наприклад, ZOG (Robertson, Newell & Ramakrishna, 1981) є система на основі кадру, що полегшує спілкування користувача з комп’ютером. Його дизайн сильно вплинув на них фактори як швидкість відповіді, необхідна для запобігання розчаруванню користувачів. Ще один приклад системи, побудованої навколо моделі канонічного користувача є автоматизований консультант Genesereth для MACSYMA, символічного математичного пакету (Genesereth, 1978). Консультант використовує чітку модель стратегії вирішення проблем, що використовується MACSYMA
для користувачів. Але, як було запропоновано вище, корисність цих канонічних моделей для системи зі спільноти неоднорідних користувачів сумнівна. Окремі моделі можуть дозволити таким системам надати кожному користувачеві більше інтерфейсу, що відповідає його потребам, ніж можна було б надати за допомогою канонічної моделі. Звичайно, потрібно демонструвати
що існують методи впровадження таких моделей, щоб вони насправді покращили ефективність роботи
системи. Різноманітність таких методів буде представлено у розділі 3.
Рішення використовувати окремі моделі користувачів має глибокий вплив на інші аспекти моделювання користувачів. Якщо система має лише одну модель канонічного користувача, яку можна розробити один раз, а потім безпосередньо включати в загальну структуру системи. Якщо, з іншого боку, система, зрештою, повинна мати великий масив моделей, що відповідають кожному з її користувачів, виникає питання про те, як і ким ці моделі повинні бути побудовані. Це призводить до другого виміру в просторі моделей користувачів.
2.2. ЕКСПЛІЦИТІ МОДЕЛІ ПРОТИ ІМПЛІЦІТНИХ МОДЕЛЕЙ
Існує два способи зробити системи різними для різних користувачів. Перший – дозволити користувачам модифікувати систему відповідно до своїх вимог. Цей підхід застосовується багатьма системами, які дозволяють користувачам явно створювати власні середовища
в системі. Розглянемо, наприклад, комп’ютерну програму, яка дозволяє користувачам системи спілкуватися з кожним іншим, надсилаючи поштові повідомлення вперед-назад. Програма зберігає повідомлення у наборі файлів та забезпечує функції, за допомогою яких користувачі можуть читати повідомлення, відповідати на них тощо. Такі системи часто дозволяють користувачам встановлювати параметри системи для визначення таких речей, як поля повідомлень, які відображатимуться під час друку повідомлення. A набагато більший ступінь персоналізації забезпечують такі системи, як більшість реалізацій програмування мовою LISP, що дозволяє користувачам вказувати довільно складну програму, яка буде автоматично виконуватися щоразу, коли користувач потрапляє в систему. За допомогою цього засобу користувач може створювати власні процедури, змінювати системні змінні, або визначити власні символи. Цей самий підхід можна побачити в багатьох системах “персоніфікованої бази даних” (Mittman &
Борман, 1975). У цих системах персоналізація походить від того, що кожен користувач може явно вибрати
документи та інформацію, що його цікавлять, і зберігати їх у приватній базі даних.
Але такий підхід залишає досить велику відповідальність в руках користувача і, мабуть, для нього не підходять
системи, які очікують справді наївних користувачів, тобто людей, які використовуватимуть систему лише один раз, а може, два-три рази, оскільки нетривіальний обсяг знань необхідний для того, щоб одночасно знати, що потрібно вказати, і як це вказати.
Інший спосіб вирішити проблему персоналізації – надати системі достатньо інформації про користувача, що він може взяти на себе власну персоналізацію. Це можна зробити тривіально або розумно. A тривіальний приклад – це програма, яка просить користувача оцінити рівень своєї кваліфікації в системі. Потім програма використовує
цей рівень, щоб визначити, скільки інформації надавати в повідомленнях про помилки. Програма по суті містить
моделі того, скільки інформації вже є на кожному рівні.
У багатьох системах необхідний більш досконалий підхід до автоматичного моделювання користувачів, щоб мати справу з обома, тому що доречна потреба в додатковій інформації про кожного користувача та э проблема, що користувачі не завжди можуть сказати системі, що це таке
потрібно знати. Приклади цієї останньої проблеми часто трапляються в області комп’ютерних інструкцій (CAI). A
Система CAI повинна знати, що кожен студент знає, не знає і знає неправильно. Студент, на жаль, не завжди знає те, чого не знає, а тим більше те, що знає неправильно.
Звичайно, студенти не самотні у відсутності знань про себе. Існує багато доказів в психологічній літературі на підтримку твердження про те, що люди не є надійними джерелами інформації самі [див., наприклад, Nisbett & Wilson (1977) та McGuire & Padawer-Singer (1976)]. На додаток до відсутністі точності, що властива явним моделям, є ще одна думка, яка аргументує допущення системи будувати власні моделі користувачів самостійно. Люди не хочуть зупинятися і відповідати на велику кількість питань, перш ніж вони зможуть отримати
з того, для чого вони намагаються використовувати систему. Це особливо стосується людей, які мають намір використовувати систему лише кілька разів і лише на короткі періоди. Щоб найкраще обслуговувати цих користувачів, система повинна сформувати якнайкраще
локальну початкову модель, наскільки це можливо, і дозвольте користувачеві негайно почати використовувати систему. Ця початкова модель може базуватися на
відомих характеристиках загальної спільноти системи користувачів, незалежно від додаткової інформації, що вже існує в системі, що має характеристики про кожного окремого користувача (наприклад, його посаду) та набір фактів, що характеризують нового користувача системи.
Коли людина взаємодіє з системою, вона надає їй додаткову інформацію про себе. По мірі придбання цього
інформації, система може поступово оновлювати свою модель користувача, поки врешті-решт не стане моделлю цього особистість на відміну від канонічного користувача. Використовуючи такий підхід, найбільше зусиль буде витрачено на побудова моделей частих користувачів, тоді як на моделі вкрай рідкісних витрачається значно менше зусиль користувачів, моделі, які мали б незначну вигоду в загальному задоволенні користувачів.
Найважливішим наслідком вибору дозволити системі побудувати власну модель користувача tJte, засновану на
взаємодія між ними полягає в тому, що більша частина інформації, що міститься в моделі, буде здогадами. Таким чином система повинен мати в якийсь спосіб представити, наскільки впевнена у кожному факті, на додаток до способу вирішення конфліктів та оновлення моделі у міру появи нової інформації. Розділ 3 запропонує кілька способів зробити це.
2.3. Довгострокові моделі проти короткострокових моделей.
Обговорюючи перші два з цих трьох вимірів, можна було стверджувати, що це одна з форм моделювання користувачів привести до більш придатної для життя системи, ніж інша. При обговоренні цього третього виміру це вже не так. В порядку щоб розумно взаємодіяти з користувачем, система повинна мати доступ до найрізноманітнішої інформації про нього, починаючи від різних, відвідносно, довготривалих фактів, таких як рівень його математичної вишуканості, до досить короткочасних фактів, таких як темою останнього речення, яке ввів користувач. Хоча вся ця інформація може сприяти пристосованості а системі, корисно, принаймні на початку вивчення теми моделювання користувачів, відокремити
проблема виведення довготривалих моделей від проблеми виведення короткотермінових моделей, оскільки різні методи можуть бути доречним для вирішення двох проблем.
Ймовірно, є розумним вимагати, щоб зусилля, витрачені на прийняття рішення про певний факт щодо користувача, були приблизно пропорційно кількості часу, який цей факт зможе використовувати. В одній крайності важливо, щоб це було таким, що не трапляється так багато часу, що витрачається на спроби зробити висновок про те, що факт вже не актуальний. В іншій крайності, може бути розумно витратити багато часу, розподіленого на багато сесій, щоб сформувати точну модель деяких по суті постійні характеристики.
Зусилля присвячені як довгостроковому, так і короткостроковому моделюванню індивідуальних користувачів. Короткочасне моделювання
є важливим у розумінні природничого мовного діалогу. Розглянемо, наприклад, такий обмін:
Замовник:
Скільки коштує квиток до Нью-Йорка?
Діловод
Сто доларів.
Клієнт: Коли наступний літак?
Діловод
Наступний літак повністю заброньований, але на цьому ще є місце
відправляється о 8:04.
Замовник:
Добре, візьму. це.
Для того, щоб відповісти на це, службовець повинен був звернутися до моделі поточної мети клієнта, потрапивши до Нью-Йорка. Було б недоречним відповісти буквально на запитання і сказати просто 6:53. Якщо комп’ютерні системи збираються виконувати завдання клерка в цьому прикладі, тоді їм теж потрібно буде вміти будувати та використовувати моделі цілей своїх користувачів. Але моделі таких речей, як поточні цілі, досить короткострокові для використання. Той самий клієнт міг би з’явитись завтра, маючи намір зустрітися з кимось із Нью-Йорка, а отже очікуючи іншої відповіді. Таким чином, для сприйняття таких цілей необхідно розробити надзвичайно чуйні методи щоб помітити, коли вони змінюються. Детальніше розширені обговорення подібних питань див. У Perroult, Allen & Коен (1978) та Манн, Мур та Левін (1977).
Але багато систем могли б корисно використовувати велику кількість набагато стабільніших знань про своїх користувачів. Ці довгострокові моделі можуть бути отримані протягом ряду взаємодій між системою та її користувачами. Такі моделі можуть містити таку інформацію, як рівень знань користувача з комп’ютерними системами загалом, його досвід
з цією системою, зокрема, та його знайомство з основним доменом завдання системи. На додаток до цих загальних речей, які можуть бути корисними в самих різних системах, моделі користувачів, що використовуються певною системою часто повинні містити конкретну інформацію, що стосується системи та сфери її завдань. Наприклад, у Програма бібліотекаря, яка буде обговорена в розділі 4, кожна модель користувача містить інформацію про такі речі, як перевага книгам із швидкоплинними сюжетами та рівнем толерантності до описів насильства.
2.4. ОГЛЯД ПРОСТОРУ
На рисунку 1 показано вісім класів моделей користувачів, породжених трьома дихотоміями, про які ми щойно обговорювали з кількома прикладами кожного. Решта цієї статті буде зосереджена на нижньому правому куті.

Фіг. 1. Простір моделей користувачів.
3. Деякі прийоми побудови моделей користувачів
Окресливши як необхідність моделювання користувачів, так і типи підходів, які можна застосувати до нього, деякі з них тепер можна представити конкретні методики, які можна використовувати для такого моделювання. У цьому розділі наведено різноманітні з них будуть розглянуті методи:
- визначення словникового запасу та понять, що використовуються користувачем.
- оцінка відповідей, якими користувач здається задоволеним.
- використання стереотипів для генерації багатьох фактів із кількох.
Ці методи поділяються на дві широкі групи: методи виведення окремих фактів на час і методи для виведення цілих скупчень фактів одночасно. Наступні два розділи обговорюють ці два види техніки.
3.1. ВИМИНЮЮЧІ ФІЗИЧНІ ФАКТИ
Одним з найпростіших способів отримання інформації про користувача є погляд на те, як він використовує систему. Хтось хто починає сеанс із серії розширених команд, напевно, фахівець. Хтось, чиї перші кілька спроб
Команди форми відхиляються системою, ймовірно, новачок і потребує певної допомоги. Простий спосіб реалізації користувацьке моделювання на основі такого роду інформації полягає у створенні словника системних команд, опцій тощо далі, і пов’язувати з кожним елементом вказівку на те, яку інформацію надає використання цього товару про його користувача.
Ця інформація може мати різні виміри, наприклад, знання системи та експертиза системи як основне завдання. Отримавши цю інформацію, вона може бути використана для розшифровки помилок користувача та для створення повідомлень з правильним рівнем опису.
Інший спосіб, яким користувачі надають інформацію про себе, – це шаблон їхніх команд. Припустимо, a користувач запитує у системи певну інформацію. Якщо він отримає те, що хоче, він або піде, або буде продовжувати своє наступне прохання. Але якщо він не отримає бажаного, то, швидше за все, спробує реструктуризувати своє прохання іншою спробою щоб отримати те, що він хотів. Ця спроба повинна сигналізувати системі, що вона не задовольнила потреби користувача першою відповіддю.
Застосування обох цих методів можна проілюструвати коротким оглядом системи, якою ми зараз збудуємо
будинок, як інтерактивна допомога для системи форматування документів, Scribe (Reid, 1980). Користувачі цієї системи можуть задавати такі питання, як:
- Як я можу отримати сформований індекс?
- Чому поля так широкі?
- Яка різниця між командою itemize та enumerate?
Система зберігає свої знання про Scribe як набір правил умови дії. У найпростішому вигляді ці правила містять одну команду Scribe як їх умову, і відповідна дія описує ефект, який виробляє команди. Однак спосіб роботи більшості команд визначається поточними значеннями деякої кількості внутрішніх системних змінних, тому їх теж слід згадати як частину умов правил. Це часто означає, що кілька правил, кожна з яких має різні умови, описують роботу однієї і тієї ж команди Scribe.
Опис функціонування системи згідно з цими правилами є ієрархічним. Дії, зазначені в iri багатьох правила не є примітивними діями, такими як розміщення персонажа в певному місці сторінки, а, скоріше, більш дії високого рівня, часто інші команди Scribe, ефекти яких, у свою чергу, описуються додатковими правилами. Дієвим
компонентом багатьох правил є встановлення деякої системної змінної, яка буде пізніше впливати на роботу інших правил.
Така ієрархічна організація інформації в системі дає можливість системі відповісти питання на багатьох різних рівнях деталізації. Так, наприклад, якщо системі задається питання “чому”, наприклад “Чому настільки широкі поля? “, вона може відповісти, вказавши умови, які спричинили спрацьовування певного правила (наприклад “Значення lmarg дорівнює 10, а значення rmarg дорівнює 10”) або воно може повернутися назад до правил, щоб визначити, як ці умови могли здійснитися. Відповідним рівнем, на якому можна відповісти на конкретне запитання, є функція рівня самого питання та рівня знань користувача, який задав питання. Щоб щоб мати можливість визначитися з правильним рівнем, система підтримує словник, що містить запис для кожного з речей що може мати місце в правилах – і як дії, і як умови. З кожним записом пов’язана інформація, яка описує, коли може бути доречним згадати пов’язане поняття в поясненні. Наприклад, кожна концепція має рейтинг, який описує, наскільки експертом повинна бути людина в Scribe, щоб мати можливість зрозуміти пояснення з його точки зору. Таким чином, багато внутрішніх системних змінних мають дуже високі рейтинги, в той час як простий користувач має дуже низькі команди. Кожна концепція також має окремий рейтинг, який описує рівень витонченості роботи з комп’ютерними системами, необхідними для його розуміння. Наприклад, вхідні файли Scribe – це блокові структури та Scribe їх обробка слідує за стандартною моделлю блокової структури. Програміст, навіть якщо він був початківцем
користувачем, зрозумів би пояснення в цих термінах, тоді як більш досконалий друкар- може не зрозуміти.
Щоразу, коли система довідки намагається знайти відповідь на питання, вона спочатку знаходить правило (або правила), яке стосується конкретної ситуації. Потім він розглядає поняття, згадані в цих правилах, і порівнює те, що їм відомо про них на те, що він знає про користувача, який задав питання. Якщо рівні збігаються, негайно генерується відповідь. Якщо вони цього не роблять, система здійснює ланцюжок правил, рухаючись вгору або вниз в ієрархії, доки це не відбувається, що вона
знаходить пояснення на правильному рівні.
Звичайно, цей метод передбачає, що система довідки має модель рівня витонченості користувача. Як і чи можна побудувати таку модель? На щастя, той самий словник понять, який використовувався при використанні
моделлю також може бути використаний для її побудови. Коли користувач задає питання, він формулює його з точки зору спостережуваних дій (таких як символи на сторінці), команди Scribe та параметри Scribe. Тоді система довідки відповідає цьому питанню до бази правил у спробі відповісти на нього. Для цього він шукає кожен із елементів питання у своєму словнику (який також служить показником правил). Люди часто посилаються на поняття, простіші за більшість складних, які вони розуміють, але вони не говорять про поняття, складніші за зрозумілі. Тому система може почати будувати свої моделі нового користувача, беручи значення, пов’язані з першими поняттями, що він згадує. Якщо згодом згадати більш складні концепції, можна підняти модель рівня знань користувача.
Модель користувача також може бути змінена, як було запропоновано вище, спостерігаючи за шаблонами запитань користувача. Припустимо, система неправильно оцінює рівень користувача і відповідає на його перше запитання, посилаючись на системний параметр, який
для користувача нічого не означає. Наступне запитання користувача майже напевно буде посилатися на цей параметр при спробі з’ясуйте, що це означає. Коли система побачить це, вона може зробити висновок про помилковість своєї моделі, а потім змінити її коли виявляє рівень пояснення, яким користувач задоволений. Подібним чином, якщо система недооцінює знання користувача, це дасть йому досить широкі загальні відповіді, він попросить більш конкретну інформацію, і
тоді система може оновити свою модель.
Цей тип моделювання користувачів дуже простий. Це робить, майже напевно, невиправданим припущення, що існує фіксований порядок, коли люди дізнаються щось про систему. Хоча це припущення, ймовірно, хибне, це не так абсолютно неправильно. Альтернативним підходом було б побудувати для кожного користувача детальну модель того, що саме він знає. Цей підхід необхідний у системах CAI, які повинні контролювати навчальні заняття за допомогою таких моделей [див., наприклад, Self (1977)]. Але такий підхід є дуже дорогим, як з точки зору часу, необхідного для побудови моделі та простіру, необхідних для їх зберігання для великої кількості користувачів. Відносини між користувачем та системою набагато більш вільні в контексті системи довідки, ніж у системі CAI. Користувач зберігає контроль над
взаємодією, і замість того, щоб використовувати у зосереджених сесіях для засвоєння ідей, зазвичай використовує довідкові системи, щоб епізодично вирішувати певні проблеми. Таким чином, потреба в точній моделі знань користувача є менш суворою.
Хоча, звичайно, немає чітко визначеної лінії, яку можна провести між цими двома типами систем, вона все ж з’являється що в багатьох ситуаціях для довідкової системи можуть бути корисними неповні моделі користувачів.
3.2. ВИКОРИСТАННЯ СТЕРЕОТИПІВ, ЩОБ ОДНОЧАСНО ДОПУСКАТИ БАГАТО РЕЧЕЙ
Методи, які обговорювались дотепер, дозволяють системі зробити окремі факти що до користувача. Але якщо
модель користувача повинна бути дуже складною, виникає питання про те, як зібрати всю необхідну інформацію протягом розумного періоду часу. Можливо, користувач матиме лише кілька розв’язок із системою, тому моделювання для користувача потребує багатьох
взаємодій для побудови початкової моделі і буде мало корисною. На щастя, у багатьох ситуаціях це можна спостерігати з невеликою кількістю фактів, і з них з достатньою мірою точності вивести набір додаткових фактів. Людські ознаки не розподіляються повністю навмання серед популяції. Швидше вони часто трапляються скупченнями. Ці кластери можуть виникати з різних причин, таких як існування одного фактора, який спричиняє кілька рис що присутній відразу, або існування причинно-наслідкового ланцюга серед самих рис. Наприклад, людина заможна ймовірно, подорожувала більше, ніж інша людина, яка є дуже бідною. Люди представляють такі знання про риси, що зустрічаються одночасно, у колекції стереотипів. Хоча слово стереотип має багато негативних асоціацій, тому важливо обмежити його використання тут суто описовим перерахування набору рис, які часто трапляються разом. З цієї точки зору стереотип – це просто спосіб фіксуючи деякі структури, які існують у навколишньому світі. З останніх кількох десятиліть роботи зі штучного інтелекту, ми прийшли до розуміння величини знань, необхідних для міркування про світ. На щастя, ми також виявили, що це знання має велику структуру, яка, якщо і може бути захопленим, але
значно обмежує речі, які слід враховувати в будь-який час. Наприклад, кілька подій не може траплятися навмання. Натомість поширені схеми подій, такі як вхід до ресторану, отримання меню, замовлення, споживання їжі та оплата. Ці моделі подій призвели до розробки сценаріїв (Schank & Abelson, 1977), які виявились надзвичайно корисними при побудові програм для розуміння описів подій такі як ті, що зустрічаються в газетних оповіданнях. Стереотипи забезпечують подібну структуру інформації про людей. Просто оскільки сценарії корисні для міркувань про події, необхідні для розуміння газетних історій, стереотипи корисні для міркувань про людей, необхідних для побудови моделей користувачів. Зокрема, вони можуть забезпечити спосіб формування правдоподібних висновків про ще небачені речі на основі речей, що були, що спостерігалися.
Стереотип представляє сукупність рис. Він може бути представлений як набір пар атрибут-значення. Ми будемо
називати кожен такий атрибут фацетом (гранею). Модель окремого користувача також може бути представлена у вигляді набору граней, заповнених значеннями. Грані стереотипів, які використовує система, повинні відповідати граням моделей користувачів, побудованих системою. Наприклад, однією з рис, яку може бути корисним розглянути, є рівень досвіду користувача з конкретною системою. Отже, моделі окремих користувачів, а також відповідні стереотипи міститимуть аспект “досвіду”, які можуть приймати значення, скажімо, від 1 до 10.
Деякі риси можуть бути легко помітні. Вони послуговують пусковими механізмами, що викликають активацію всього стереотипу. Оскільки наявність ознаки може наводити на думку лише про певний стереотип, а не абсолютний доказ цього, кожен тригер пов’язав із собою рейтинг, який є грубим показником ймовірності наявності стереотипу доречно, враховуючи те, що тригер спостерігався. Звичайно, справа не лише у взаємозв’язку між тригерами та стереотипами, що в кращому випадку сугестивне. Стереотип говорить лише про те, що сукупність рис часто зустрічається разом, не те що
вони завжди це роблять. Отже, з кожним аспектом стереотипу має бути рейтинг, який оцінює ймовірність що
відповідна риса існує з огляду на відповідність стереотипу.
Стереотипи представляють структуру серед рис. Часто існує додаткова структура, якою можна захопити що
представляючи колекцію стереотипів як ієрархію. Інформація в дуже загальних стереотипах може використовуватися хіба що суперечливу інформацію пропонують більш конкретні стереотипи. Найзагальніший стереотип, доступний системіможе представляти модель канонічного користувача. Таким чином, навіть не маючи багато інформації, система, побудована на стереотипах, буде робити не гірше, ніж побудована на традиційній вбудованій моделі канонічного користувача.
Одна з найважливіших проблем, яку слід вирішити в будь-якій системі моделювання користувачів на основі висновків з поведінка користувача – це спосіб виявлення та вирішення конфліктів між умовиводами. Щоб полегшити це, рейтинги, що є, прикріплені як до тригерів, так і до кожного передбачення (аспекту) кожного стереотипу. Крім того, кожна грань особистості модель користувача повинна містити не просто значення, а й оцінку довіри системи до цього значення (яке може бути
використовується для визначення того, наскільки величина повинна бути дозволена впливати на ефективність загальної системи) та перелік причин, чому це вважається цінністю. Цей перелік причин важливий. Наприклад, припустимо стереотип активується в результаті якоїсь спостережуваної риси користувача. Цей стереотип передбачає значення для певної грані, але
модель системи користувача вже містить інше значення для цієї грані. Якби система запам’ятала, куди вона відправила це значення, можливо, можна досить легко вирішити конфлікт, як, наприклад, якщо раніше значення
активованого стереотипу, більш загальніше, ніж того, що тільки активується.
Іноді кілька різних стереотипів можуть передбачати одне і те ж значення, а не різні для аспекту. У цьому випадку рівень довіри системи до прогнозування може бути вищим, ніж це було б, якби існувало лише одне джерело
інформація . Оскільки для стереотипів доцільно передбачати інші стереотипи, а особливо
пар цінностей для прогнозування стереотипів, приплив нової інформації може зажадати поширення рейтингових змін по всій користувацькій моделі. Точна ступінь ефективності продовження такого поширення – це питання, яке є важливим, що потрібно визначати емпірично.
Усі ці методи комбінування висновків, запропоновані різними стереотипами, можна узагальнити, щоб сформувати основу для інтеграції більш широкого кола джерел знань про окремого користувача. Корисними, можуть бути стереотипи уможливлюючи початкову побудову моделі користувача досить швидко, але вони не усувають потребу в інших видах інформація, що включає як відповіді на прямі запитання, так і інші непрямі прийоми, обговорені вище в контекст помічника Scribe. Але одного разу кожен елемент моделі користувача супроводжується рейтингом та списком підтверджуючи це, легко додати довільні джерела знань. Нова інформація, яка підтримує старі значення змушує рейтинги, що прикріплені до значень, зростати. Нова інформація, яка конфліктує зі старими цінностями, викликає вирішення конфліктів, щоб перевірити довіру конкуруючих голосів, щоб дати настільки добру оцінку істини, як це тільки
можливо. Відповіді користувача на прямі запитання можуть мати пріоритет над простими умовиводами, що, в свою чергу, може бути, що надається пріоритет перед прогнозами стереотипів.
Досі обговорення використання стереотипів було загальним і уникало посилань на певні системи або
домени завдань. У наступному розділі – конкретна система, яка успішно використовувала стереотипи для побудови моделей своїх користувачів буде обговорюватися. Загальні моменти, згадані в цьому розділі, будуть проілюстровані на конкретних прикладах.
4. Грунді: тематичне дослідження використання стереотипів
Для тестування багатьох ідей, викладених вище, була побудована пілотна система під назвою Grundy. Грунді рекомендує романи, які люди, можливо, хотіли б прочитати. Для цього він використовує дві колекції даних:
- описи окремих книг. Кожен опис – це набір граней, заповнених відповідними значеннями.
- стереотипи, що містять грані, що стосуються смаку людей у цих книгах. З кожним стереотипом асоціюється
збір тригерів.
Крім того, Грюнді має певні знання про кожен з аспектів, які можуть мати місце у стереотипах. Це знання
використовується для вирішення конфліктів між конкуруючими умовиводами, а також для відображення інформації в моделі користувача до інформації в описах книг. Для опису Грунді що більш повний, ніж тут представлений див. Rich (1979a, b).
Коли новий користувач починає розмову з Грунді, його просять надати кілька слів, які він думає щоб забезпечити хороший самоопис. Грунді використовує ці слова як пусковий механізм для створення відповідних стереотипів, і це починається як побудова своєї користувачскої моделі. Зазвичай в цей момент активується кілька стереотипів, і часто виникають конфлікти серед їхніх прогнозів, які Грунді вирішує наскільки може. Потім Грунді оцінює (використовуючи комбінацію кількість речей, у які він вірить, і наскільки сильно він їм вірить) чи є у нього достатньо інформації для початку
рекомендування книги. Якщо це так, то процесс йде вперед. Якщо цього не сталося, він запитує у користувача ще кілька слів.
На малюнку 2 показано два стереотипи, які використовував Грунді. На малюнку 3 показано, як би виглядала модель користувача Грунді, наприклад, після того, як сказали ім’я користувача (і зробили з нього висновок, що він є жінкою), і після спеціальної активації
ЖІНКИ, ФЕМІНІСТИЧНІ та ІНТЕЛЕКТУАЛЬНІ стереотипи. Щоразу, коли Грунді активує стереотип, він також активує всі узагальнення цього стереотипу, тому стереотипи ОСВІТЕНА ОСОБА та БУДЬ-ЯКА ОСОБА (канонічна модель користувача) також були активовані. Зверніть увагу, що кожен із стереотипів містить лише деякі аспекти, що містяться в повній користувацькій моделі. Це часто трапляється, оскільки багато стереотипів стосуються лише одного (або, можливо, декількох) значущіх сторін людини.
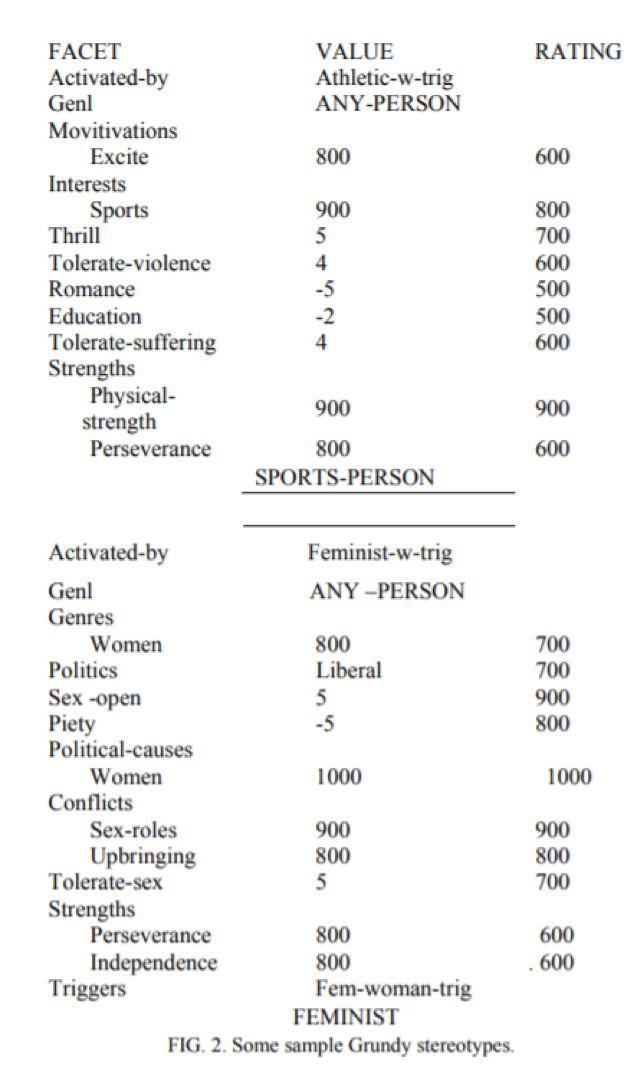
Фіг. 2. Деякі зразки стереотипів Грунді.
Після накопичення достатньої кількості інформації для початку, Грунді починає рекомендувати книги по черзі до
користувач каже йому зупинитися. Процес вибору книги триває наступним чином.
- Виберіть помітну грань у користувацькій моделі. Помітні грані – це ті, що мають невисокі значення
рейтингу.
- Використовуйте перевернутий індекс у базі даних книги, щоб вибрати всі книги, запропоновані цим конкретним фасетним значенням.
- Порівняйте кожну з обраних книг із моделлю користувача за всіма вимірами. Виключіть книги, які перевищують певні межі (наприклад, терпимість до насильства).
- З книг, які не були ліквідовані, виберіть ту, яка найкраще відповідає. Якщо він перевищує поріг
близькість збігу, рекомендуйте. В іншому випадку перейдіть до кроку 1, виберіть новий аспект і повторіть спробу.
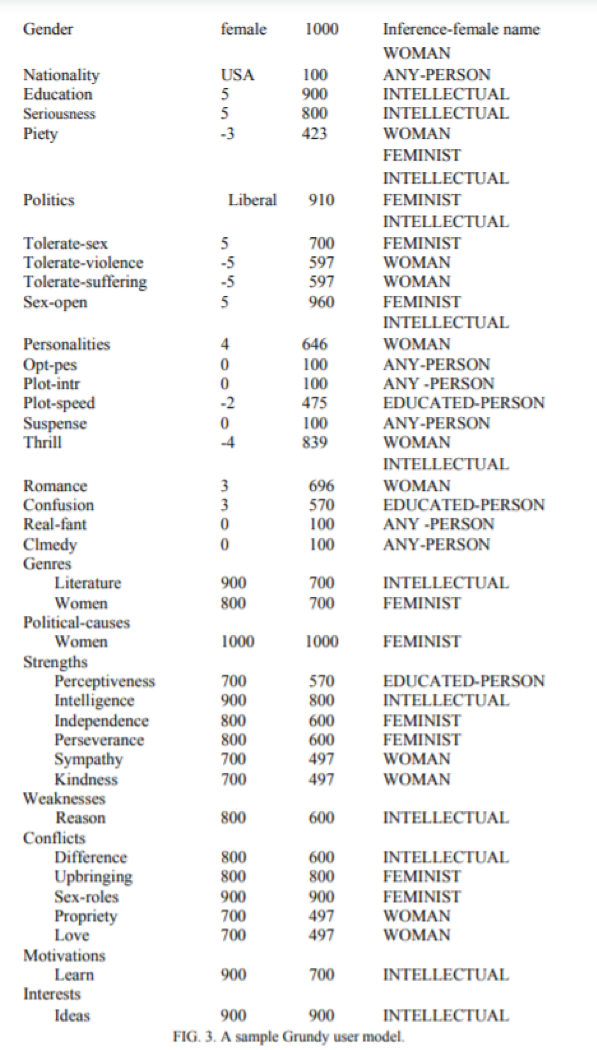
Фіг. 3. Зразок моделі користувача Grundy.
Вибравши книгу, Грунді повідомляє користувачеві ім’я автора та заголовок, а потім запитує у неї, чи вона
прочитала це раніше. Якщо вона прочитала це раніше, Грунді знає, що йде по правильному шляху. Тепер вона може зміцнити свою віру в те, що привело її до вибору цієї книги. (Див. Розділ 5 для більш детального обговорення питання модифікації бази даних Грунді.) Якщо їй книга не сподобалась, Грунді потрібно з’ясувати, чому. В ідеалі було б просто сказано: “Чому ні?”, Але набагато більше
для тлумачення відповідей на таке запитання знадобиться знання, яке має Грунді. Наприклад, хтось може сказати,
що їй не сподобалась книга, бо головний герой нагадував їй про свого стоматолога. Тож замість цього Грунді намагається з’ясуйте, яке з переконань щодо користувача привело до того що раніше він вибирав цю книгу було помилковим. Для цього він задає кілька прямих запитань, доки проблема не виявить проблему або не буде змушена поступитися. Якщо проблему знайшло, значить може
оновити як свою модель користувача, так і свою базу даних стереотипів.
Якщо користувачка каже Грунді, що вона не читала книги, тоді Грунді розповідає їй деякі речі, які, на її думку, зацікавлять її. Grundy використовує свою модель користувача, щоб вибрати, яку з характеристик книги згадати. Потім запитує користувачку, чи вважає вона, що книга їй сподобається. Цього разу, якщо вона скаже “так”, Грунді нічого не робить, оскільки позитивна відповідь базується лише на кількох фактах, які побачив користувач. Але якщо користувач каже, що книга не виглядає цікаво, то що, Grundy використовує описану вище процедуру, щоб спробувати з’ясувати, що пішло не так, щоб спробувати знайти те, щось їй більше сподобається.
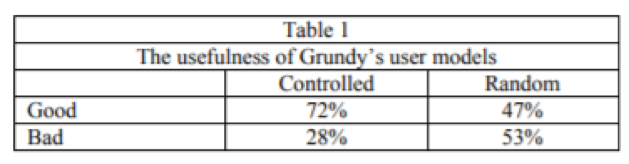
Для того, щоб перевірити корисність користувацьких моделей Grundy, був проведений експеримент, в рамках якого Grundy давав кожному своїх користувачів скільки завгодно пропозицій. Це також дало їм (кожному) кілька пропозицій, обраних навмання без допомоги користувацької моделі і запитав їх, чи добре виглядають пропозиції. Вони служили би контролем.
У таблиці 1 наведено відсоток пропозицій, які були описані як добрі, на відміну від тих, що описуються як погані
у контрольованому режимі (де модель користувача визначала вибір) та у випадковому режимі. Ці цифри це показують Grundy робить значно (p <lO-9) краще з користувацькою моделлю, ніж без неї.
Хоча моделі користувачів Грунді і не наближаються до того, щоб зафіксувати жодного з складно пов’язаних факторів, які визначають, які романи сподобаються людині, рівень успішності внесення пропозицій вказує на те, що він менш повний до користувацької моделі та може надати корисні вказівки щодо інтерактивних систем.
Таблиця 1
5. Навчання в Грунді
Стереотипи надзвичайно корисні для того, щоб система могла швидко побудувати початкову модель нового користувача, а також, щоб вона могла зайнятися будь-яким справжнім завданням. Але як ми можемо розробити точні стереотипи для використання системою? Будуть чи всі зусилля з моделювання користувачів марні, якщо стереотипи неточні? Це важливі питання, які ще потрібні повні відповіді, але досвід роботи з Грунді свідчить про те, що вони не є нездоланними перешкодами.
Початкові стереотипи Грунді представляли лише мою інтуїцію про людей та книги, які вони читали. Жодної спроби не було створено для збору будь-яких жорстких даних. Незважаючи на це, стереотипи дуже корисні. Але що цікавіше може бути відзначити, що Грунді здатний змінювати свої стереотипи на основі свого досвіду, коли цей досвід суперечить прогнозам стереотипів. Можуть бути зроблені лише досить прості модифікації. Неможливо додати грані або видалити, але значення фасети може змінюватися, як і його рейтинг.
Початковий стереотип Грунді щодо типового читача чоловічої статі вказував на те, що чоловіки люблять читати книги з швидкоплинними сюжетами, де є ще
і багато хвилювання. Це може бути правдою щодо чоловічого населення США, але чоловіків Грунді
насправді визначила не дуже широким перерізом цієї популяції; всі вони були викладачами та випускниками університету, чи студентами. Тому їм, як правило, подобаються інтелектуальні види книг, які, як правило, сильніші у філософії, ніж у сюжеті. Тому Грунді поступово модифікував свій стереотип MAN, щоб відобразити смаки населення чоловіків, якого він насправді бачив ніж деяке населення, яке я собі уявляла. Той факт, що він міг це зробити, свідчить про дві обнадійливі речі щодо суті справи використання стереотипів у системах моделювання користувачів:
- не критично, щоб були створені точні дані, що описують спільноту користувачів, для створення початкового набору
стереотипи.
- якщо в різних спільнотах використовується єдина система, її стереотипи можуть розвиватися окремо в кожній із них, де кожен характеризується досить точно.
Звичайно, можливі й інші типи навчання, яких Грюнді не робить. Grundystores зберігає всі свої користувацькі моделі, то що коли користувач повертається для наступних сеансів, не потрібно будувати нову модель з нуля. Таким чином це було б можливо будувати абсолютно нові стереотипи, спостерігаючи за типовими особливостями, які часто зустрічаються серед користувачів.
6. Висновок
У цій роботі я стверджувала, що для багатьох інтерактивних комп’ютерних систем спільнота користувачів є достатньо неоднорідною, що одна модель канонічного користувача є неадекватною. Натомість можливість формувати окремі моделі що до окремих користувачів. І тоді я показала, що крім необхідності, такі моделі також можливі, і також представлена колекція способів їх побудови та експлуатації.
Загальне в усіх цих техніках полягає в тому, що вони передбачають здогади про користувача. Ці здогадки є такими, що зроблені системою на основі її взаємодії з користувачем. Як наслідок, завжди розглядається можливість помилки, яка може бути . Для цього система повинна зробити дві речі:
- вона повинна прикріпити оцінки та обґрунтування до кожного з тих речей, у які вірить.
- вона не повинна розглядати модель користувача як фіксовану, а скоріше як те, на чому вона може постійно вдосконалюватися шляхом збору відгуків від користувача щодо кожної взаємодії.
Список літератури
CARD, SK, MORAN, TP & NEWELL, A. (1980). Модель рівня натискання клавіші для часу роботи користувача з
інтерактивні системи. Повідомлення Асоціації обчислювальної техніки, 23, 396-410.
CODD, EF (1974). Сім кроків до побачення з випадковим користувачем. У KLIMBIE, JW & KOFFEMAN, KL,
Видання, управління базою даних. Амстердам: Північна Голландія.
КАФФ, Р. Н. (1980). Для випадкових користувачів. Міжнародний журнал досліджень людина-машина, 12, 163-187.
FITTS, PM & PETERSON, J.R (1964). Інформаційна здатність дискретних рухових реакцій. Журнал
Експериментальна психологія, 67, 103-112.
ГЕНЕСЕРЕТ, М. (1978). Автоматизований консультант користувача для MACSYMA. Доктор філософії – дисертація, Гарвардський університет.
HUDGENS, GA & BILLINGSLEY, PA (1978). Стать: відсутність змінної у дослідженні людських факторів. Людськи Фактори, 20, 245-250.
LEDGARD, H., WHITESIDE, JA, SINGER, A. & SEYMOUR, W. (1980). Природна мова інтерактиву системи. Повідомлення Асоціації обчислювальної техніки, 23, 556-563.
LOO, R (1978). Індивідуальні відмінності та сприйняття дорожніх знаків. Людські фактори, 20, 65-74.
MANN, WC, MOORE, JA & LEVIN, JA (1977). Модель розуміння людського діалогу. В
Матеріали Міжнародна спільна конференція “Штучний інтелект”, 5, 77-87.
MCGUIRE, WJ & PADAWER-SINGER, A. (1976). Виділення рис у спонтанній Я-концепції. Журнал
Особистість та соціальна психологія, 33, 743-754.
MITTMAN, B. & BORMAN, L. (1975). Персоналізовані системи баз даних. Лос-Анджелес: Melville Publishing Co.
НІСБЕТ, Р. Е. & УІЛСОН, ТД (1977). Говорячи більше, ніж ми можемо знати: словесні повідомлення про психічні процеси. Психологічний огляд, 84, 231-259.
PERRAULT, C.R, ALLEN, JF & COHEN, P.R (1978). Мова виступає основою для розуміння діалогу
узгодженість. У матеріалах другої конференції з теоретичних питань обробки природної мови .
РЕЙД, БК (1980). Scribe: мова специфікації документа та його компілятор. Доктор філософії – дисертація, Карнегі-Меллон Університет.
RICH, EA (1979a). Створення та використання моделей користувачів. ‘Доктор філософії дисертація, Університет Карнегі-Меллона.
RICH, EA (1979b). Моделювання користувачів за допомогою стереотипів. Когнітивна наука, 3, 329-354.
РОБЕРТСОН, Г., НУЕЛЛ, А. і РАМАКРІШНА, К. (1981). Підхід ZOG до людини-машини
спілкування. Внутрішній журнал досліджень людина-машина, 14 (4), 461-488.
SCHANK, R C. & ABELSbN, R P. (1977). Цілі, плани, сценарії та розуміння: Дослідження людини
Структури знань. Хіллсдейл, штат Нью-Джерсі: Erlbaum Press.
САМО, JA (1977). Концепція навчання. Штучний інтелект, 9, 197-221.
СМІТ, С. (1979). Розмір листа та розбірливість. Людські фактори, 21, 661-670.