Міжнародны J. Man-Machine Studies (1983) 18, 199-214
Карыстальнікі – прыватныя асобы:
– індывідуалізацыя мадэляў карыстальнікаў
ЭЛЕН РЫЧ
Дэпартамент камп’ютэрных навук Тэхаскага універсітэта ў Осціне, Осцін, штат Тэхас, 78712, ЗША
(Атрымана 13 мая 1981 г.)
Даўно прызнана, што для стварэння добрай сістэмы, у якой чалавек і машына супрацоўнічаюць пры выкананні задання важна ўлічваць некаторыя істотныя характарыстыкі людзей. Гэтыя характарыстыкі выкарыстоўваюцца для пабудовы нейкай “мадэлі карыстальніка”. Традыцыйна мадэль, якая будуецца, з’яўляецца мадэллю кананічнай (альбо тыповы) карыстальнік. Але часта асобныя карыстальнікі настолькі адрозніваюцца, што мадэлі кананічнага карыстальніка недастаткова. Замест гэтага
мадэлі асобных карыстальнікаў неабходныя. У гэтым артыкуле прыведзены некалькі прыкладаў сітуацый, у якіх чалавек
карыстальніцкія мадэлі важныя. У ім таксама прадстаўлены некаторыя метады, якія дазваляюць пабудаваць і выкарыстоўваць такія мадэлі магчыма. Усе гэтыя метады адлюстроўваюць жаданне ўскласці большую частку цяжару пабудовы мадэляў на
сістэмы, а не на карыстальніка. Гэта прыводзіць да распрацоўкі мадэляў, якія ўяўляюць сабой калекцыі добрых здагадак пра
карыстальнік. Такім чынам, неабходныя нейкія імаверныя развагі. І паколькі мадэлі выкарыстоўваюцца для кіраўніцтва
асноўная сістэма, яны таксама павінны кантралявацца і абнаўляцца ў адпаведнасці з узаемадзеяннем паміж карыстальнікам і сістэма. Абмяркоўваецца прадукцыйнасць адной сістэмы, якая выкарыстоўвае некаторыя з гэтых метадаў.
1. Увядзенне
Даўно прызнана, што для стварэння добрай сістэмы, у якой чалавек і машына супрацоўнічаюць пры выкананні задання важна ўлічваць некаторыя істотныя характарыстыкі людзей. Сістэма можа быць закліканы скарыстацца гэтымі характарыстыкамі, а не змагацца з імі.
Традыцыйна гэта робіцца шляхам збору дадзеных аб паспяховасці сярэдняга чалавека пры выкананні розных задач у
розныя асяроддзя. Напрыклад, закон Фітса (Fitts & Peterson, 1964) абвяшчае, што чалавеку трэба час перамясціць прадмет у руцэ ў пэўную мэтавую пазіцыю прапарцыйна часопісу 2 (2А / ш), дзе А – адлегласць, якое трэба перамешчаны і w – шырыня мэты. Гэты вынік сведчыць пра тое, як хутка чалавек можа працаваць
машына можа быць павялічана за кошт павелічэння памеру мэтаў (напрыклад, кнопак і перамыкачоў), якія вырабляе аператар павінны ўдарыць. У якасці яшчэ аднаго прыкладу гэтага класа працы разгледзім вялікую колькасць дадзеных пра ўзаемасувязь паміж памер літар і іх разборлівасць (Smith, 1979). Гэтыя вынікі важныя для дызайну не толькі самых розных
машын, але і іншых артэфактаў, такіх як дарожныя знакі.
Асноўная слабасць гэтых даследаванняў заключаецца ў тым, што яны робяць здагадку, што людзі, якія ўдзельнічаюць у гэтым, складаюць аднародны набор. Згодна з гэтым здагадкай, могуць быць значэнні, якія вызначаны для характарыстыкі “тыповага” чалавека выкарыстоўваецца для распрацоўкі сістэмы, якой будуць карыстацца ўсе. Хоць у большасці выпадкаў дакладна, што, па меншай меры, для большасці людзі, сістэма для іх лепш прыстасаваная, чым была б без гэтых даследаванняў, няпраўда, што такая сістэма, верагодна, будзе лепшай, якую можна было б вырабіць. Значна лепшай была б сістэма, у якой інтэрфейс прадстаўлены кожнаму чалавеку быў прыстасаваны да яго ўласных характарыстык, а не да нейкіх абстрактных “тыповых”
чалавек. Хоць абмеркаванне індывідуальных адрозненняў сярод карыстальнікаў рэдка сустракаецца ў літаратуры пра чалавечы фактар, але яны сустракаюцца зусім не адсутнічае. Напрыклад, Hudgens & Billingsley (1978) сцвярджаюць, што сэкс з’яўляецца важнай зменнай у чалавека даследаванне фактараў. У іншым даследаванні Loo (1978) разглядаюцца індывідуальныя адрозненні ва ўспрыманні дарожных знакаў.
Адна з прычын таго, што такія даследаванні былі рэдкімі, заключаецца ў тым, што яны часта альбо занадта дарагія, альбо немагчымыя фізічныя прылады – узровень гнуткасці, які яны прапануюць. Аднак, як мы пачынаем бачыць усё больш і больш людзей узаемадзеянне з машынамі, якія апасродкаваны кампутарамі пад праграмным кантролем, становіцца магчымым забяспечыць гнуткасць, неабходная для сапраўды персаналізаваных сістэм.
У якасці простага прыкладу зноў разгледзім пытанне памеру і разборлівасці літар. Калі літары дысплея знаходзяцца вырабленыя з выкарыстаннем стандартнага святлодыёднага дысплея, яны будуць аднолькавага памеру для ўсіх чытачоў. Але выкажам здагадку, літары ёсць адлюстроўваецца на ЭПТ, кіраванай кампутарам. Цяпер лініі можна праводзіць усюды, дзе неабходна вырабляць шырыню разнастайнасць памераў літар паводле запыту асобных карыстальнікаў.
У апошні час дызайнеры карыстацка-камп’ютэрных інтэрфейсаў пачалі канцэнтраваць увагу на патрэбах пэўных тыпаў
карыстальнікі. Часта абмяркоўваецца адна група “выпадковых” карыстальнікаў, ад якіх нельга чакаць выкарыстоўваць сістэму з вялікай доляй рэгулярнасці [гл., напрыклад, Codd (1974) і Cuff (1980)]. Тады гэтая група павінна быць супрацьпастаўленым менш добра вывучаным відам, звычайным, дасведчаным карыстальнікам. На жаль, мала сістэм будзе выкарыстоўваецца выключна людзьмі аднаго класа. І, падобна, функцыі сістэмы, якія палягчаюць жыццё аднаму тыпу карыстальнік адпаведна робіць яго больш цяжкім для іншага. Напрыклад, адно даследаванне эфектыўнасці карыстальнікаў-экспертаў
пры заданні рэдагавання тэксту (Card, Moran & Newell, 1980) мяркуе, што колькасць націсканняў клавіш, неабходнае для выканання эксплуатацыя павінна быць зведзена да мінімуму. Чарговае даследаванне людзей, якія толькі вучацца карыстацца рэдактарам (Ledgard, Whiteside, Singer & Seymour, 1980) мяркуе, што трэба выкарыстоўваць англамоўныя поўнакамандныя словы. Гэтыя супярэчлівыя патрабаванні паказваюць на неабходнасць сістэмы, якая можа адрознівацца для розных карыстальнікаў.
Шчасце, што камп’ютэр забяспечвае сродкі для павелічэння персаналізацыі, бо ён таксама вырабляе большыя патрэба ў ім за кошт павелічэння кола задач, для якіх людзі могуць спадзявацца атрымаць прыбытак, працуючы з машынамі. Задачы, якія раней выконваліся людзьмі, напрыклад, збіралі патрэбную інфармацыю з нейкай базы дадзеных, зараз робіцца з дапамогай кампутараў. Людзі, якія выконвалі гэтыя задачы, маглі задаволіць разнастайныя патрэбы іншыя людзі, з якімі яны мелі справу. Калі машыны возьмуцца за гэтыя задачы і задаволена з імі справяцца, яны таксама гэта зробяць павінны быць у стане адаптавацца да індывідуальных патрэб. Для гэтага ім трэба будзе выкарыстоўваць мадэлі індывідуальных карыстальнікаў, з якімі яны сутыкаюцца. Гэта запатрабуе пашырэння традыцыйнага паняцця “мадэль карыстальніка”.
У астатняй частцы гэтага артыкула мы разгледзім праблему мадэлявання карыстальнікаў менавіта ў кантэксце кампутара
праграмныя сістэмы, як з-за ўсё большага выкарыстання такіх сістэм вялікімі групамі людзей, так і з-за уласцівая гнуткасць такіх сістэм, што дазваляе эфектыўнае мадэляванне.
2. Прастора мадэляў карыстальнікаў
Тэрмін “мадэль карыстальніка” можа быць выкарыстаны для апісання самых розных ведаў пра людзей. Выкарыстанне карыстальніцкіх мадэляў ахоплівае не менш шырокі дамен. Суадносіны паміж гэтымі разнастайнымі структурамі можна ўбачыць даволі лёгка, калі Сусвет “карыстальніцкіх мадэляў” характарызуецца як трохмерная прастора. Памеры, кожны з якіх будзе рзгледжаныя больш падрабязна ніжэй:
- адна мадэль аднаго, кананічнага карыстальніка супраць калекцыі мадэляў асобных карыстальнікаў.
- мадэлі, відавочна ўказаныя альбо дызайнерам сістэмы, альбо самімі карыстальнікамі, у параўнанні з мадэлямі, выведзенымі
сістэма на аснове паводзін карыстальнікаў.
- мадэлі даволі доўгатэрміновых характарыстык карыстальнікаў, такіх як сферы інтарэсаў альбо экспертызы, супраць мадэляў адносна кароткатэрміновыя характарыстыкі карыстальніка, такія як праблема карыстальнік у цяперашні час спрабуе вырашыць.
Ёсць і іншыя істотныя адрозненні паміж сістэмамі, якія выкарыстоўваюць гэтыя розныя тыпы карыстацкіх мадэляў, але яны вынікаюць з гэтых асноўных адрозненняў. Сістэмы з адной мадэллю кананічнага карыстальніка могуць мець гэтую мадэль
пастаянна ўбудаваны ў сябе, тады як сістэмы з мадэлямі асобных карыстальнікаў павінны будаваць мадэль на ляту, і таму павінны растлумачыць спосабы ўплыву мадэлі на прадукцыйнасць агульнай сістэмы.
Сістэмы, якія выцягваюць мадэль карыстальніка з паводзін карыстальніка, павінны сур’ёзна змагацца з праблемамі няправільных альбо супярэчлівая інфармацыя, якая вынікае з высноў, якія прывялі да мадэлі. Сістэмы з відавочна заяўленым карыстальнікам інфармацыя, з іншага боку, дазваляе пазбегнуць многіх з гэтых праблем.Сістэмы, якія займаюцца кароткатэрміновымі ведамі, павінны паспяхова справіцца з праблемай выяўлення, калі што-небудзь зменіцца, у той час як больш доўгатэрміновыя сістэмы могуць вытанчанасць гэтага пытання. Але паколькі гэтыя адрозненні зводзяцца да трох, выкладзеных вышэй, на іх не трэба арыентавацца відавочна.
У наступных трох раздзелах коратка абмяркоўваецца, як можна выбраць лепшае становішча ў гэтай трохмернай прасторы.
2.1. КАНАНІЧНЫЯ АД ІНДЫВІДУАЛЬНЫЯ МАДЭЛІ
Гэты памер характарызуе асноўную розніцу паміж “класічнай” працай чалавечых фактараў і больш гнуткай мадэлі, неабходныя для прадастаўлення індывідуальнага інтэрфейсу, які дазваляе праграмнае кіраванне.Разнастайнасць камп’ютэрных сістэм былі распрацаваны вакол кананічнай мадэлі карыстальніка. Напрыклад, ZOG (Robertson, Newell & Ramakrishna, 1981) сістэма на аснове кадра, якая палягчае сувязь карыстальнік- кампутар.Такое ўздзеянне моцна паўплывала на яго дызайн фактары, як хуткасць адказу, неабходная для прадухілення расстройстваў карыстальнікаў. Яшчэ адзін прыклад сістэмы, пабудаванай вакол a мадэль кананічнага карыстальніка – аўтаматызаваны кансультант Genesereth для MACSYMA, сімвалічнага матэматычнага пакета (Genesereth, 1978). Кансультант выкарыстоўвае відавочную мадэль стратэгіі вырашэння праблем, якую выкарыстоўвае MACSYMA
карыстальнікі. Але, як было прапанавана вышэй, карыснасць гэтых кананічных мадэляў для сістэмы з a ёсць неаднародная супольнасць карыстальнікаў. Асобныя мадэлі дазваляюць такім сістэмам прадастаўляць кожнаму карыстальніку больш інтэрфейсу адпавядае яго патрэбам, чым можна было б даць з выкарыстаннем кананічнай мадэлі. Зразумела, трэба дэманстраваць што існуюць метады рэалізацыі такіх мадэляў, каб яны сапраўды палепшылі прадукцыйнасць сістэма. Разнастайнасць такіх метадаў будзе прадстаўлена ў раздзеле 3.
Рашэнне выкарыстоўваць асобныя мадэлі карыстальнікаў аказвае глыбокае ўздзеянне на іншыя аспекты мадэлявання карыстальнікаў. Калі а сістэма валодае толькі адной мадэллю кананічнага карыстальніка, якая можа быць распрацавана адразу, а потым непасрэдна уключаны ў агульную структуру сістэмы. Калі, з іншага боку, сістэма ў канчатковым рахунку павінна валодаць вялікім масівам мадэляў, якія адпавядаюць кожнаму з карыстальнікаў, пытанне аб тым, як і кім гэтыя мадэлі павінны быць пабудаваны узнікае. Гэта прыводзіць да другога вымярэння ў прасторы карыстальніцкіх мадэляў.
2.2. EXPLICIT VS IMPLICIT MАДЕЛЯУ
Ёсць два спосабы зрабіць сістэмы рознымі для розных карыстальнікаў. Адзін з іх – дазволіць карыстальнікам мадыфікаваць сістэму ў адпаведнасці з патрабаваннямі самі. Такі падыход выкарыстоўваюць многія сістэмы, якія дазваляюць карыстальнікам выразна ствараць свае ўласныя асяроддзя унутры сістэмы. Разгледзім, напрыклад, камп’ютэрную праграму, якая дазваляе карыстальнікам сістэмы мець зносіны з кожным іншыя, адпраўляючы паштовыя паведамленні туды-сюды. Праграма захоўвае паведамленні ў наборы файлаў і прадастаўляе функцыі, з дапамогай якіх карыстальнікі могуць чытаць паведамленні, адказваць на іх і г.д. Такія сістэмы часта дазваляюць карыстальнікам усталёўваць сістэмныя параметры для вызначэння такіх рэчаў, як палі паведамленняў, якія будуць адлюстроўвацца пры раздрукоўцы паведамлення. А значна большая ступень персаналізацыі забяспечваецца такімі сістэмамі, як большасць рэалізацый праграмавання мова LISP, якія дазваляюць карыстальнікам вызначаць адвольна складаную праграму, якая будзе аўтаматычна выконвацца кожны раз, калі карыстальнік уваходзіць у сістэму. З дапамогай гэтага сродку карыстальнік можа ствараць свае ўласныя працэдуры, змяняць сістэмныя зменныя, альбо вызначыць уласныя сімвалы. Гэты ж падыход можна ўбачыць у многіх сістэмах “персаналізаванай базы дадзеных” (Mittman & Борман, 1975). У гэтых сістэмах персаналізацыя зыходзіць з таго, што кожны карыстальнік можа відавочна выбраць цікавяць яго дакументы і інфармацыю і захоўваць іх у прыватнай базе дадзеных.
Але такі падыход пакідае даволі вялікую адказнасць у руках карыстальніка і, верагодна, не падыходзіць для гэтага сістэмы, якія чакаюць сапраўды наіўных карыстальнікаў, г.зн. людзей, якія будуць выкарыстоўваць сістэму толькі адзін, а можа, два-тры разы, паколькі нетрывіяльны аб’ём ведаў неабходны для таго, каб ведаць, што трэба ўдакладніць, і як гэта ўказаць.
Іншы спосаб падыходу да праблемы персаналізацыі – даць сістэме дастаткова інфармацыі карыстальнікі, якія могуць узяць на сябе адказнасць за ўласную персаналізацыю. Гэта можна зрабіць банальна альбо разумна. А трывіяльны прыклад – гэта праграма, якая просіць карыстальніка ацаніць узровень ведаў у сістэме. Затым праграма выкарыстоўвае гэты ўзровень, каб вызначыць, колькі інфармацыі прадастаўляць у паведамленнях пра памылкі. Праграма па сутнасці ўтрымлівае мадэлі таго, наколькі вялікай колькасцю інфармацыі валодаюць людзі на кожным узроўні.
У многіх сістэмах неабходны больш дасканалы падыход да аўтаматычнага мадэлявання карыстальнікаў, каб мець справу з абедзвюма неабходнасць атрымаць дадатковую інфармацыю пра кожнага карыстальніка і праблема, з-за якой карыстальнікі не заўсёды могуць сказаць сістэме, што гэта такое трэба ведаць. Прыклады гэтай апошняй праблемы часта сустракаюцца ў галіне камп’ютэрных інструкцый (CAI). А Сістэма CAI павінна ведаць, што кожны студэнт ведае, што не ведае і ведае няправільна. Студэнт, на жаль, не заўсёды ведае, чаго не ведае, а тым больш што ведае няправільна.
Зразумела, студэнты не адзінокія ў недахопе ведаў пра сябе. У гэтым шмат доказаў псіхалагічная літаратура ў падтрымку сцвярджэння, што людзі не з’яўляюцца надзейнымі крыніцамі інфармацыі самі [гл., напрыклад, Nisbett & Wilson (1977) і McGuire & Padawer-Singer (1976)]. У дадатак да адсутнасць дакладнасці, уласцівая відавочным мадэлям, ёсць яшчэ адно меркаванне, якое сцвярджае, што дазваляе сістэме пабудаваць свае карыстальніцкія мадэлі самастойна. Людзі не хочуць спыняцца і адказваць на вялікую колькасць пытанняў, перш чым атрымаць магчымасць на тым, з чым яны спрабуюць выкарыстоўваць сістэму. Асабліва гэта тычыцца людзей, якія маюць намер выкарыстоўваць сістэма ўсяго некалькі разоў і толькі на кароткі перыяд. Для найлепшага абслугоўвання гэтых карыстальнікаў сістэма павінна фармавацца як добра пачатковая мадэль, як толькі можа, і дазвольце карыстальніку неадкладна пачаць выкарыстоўваць сістэму. Гэтая пачатковая мадэль можа быць заснавана на вядомыя характарыстыкі агульнай супольнасці карыстальнікаў сістэмы, якая б дадатковая інфармацыя ўжо не была ў сістэме мае пра кожнага асобнага карыстальніка (напрыклад, яго пасаду) і набор фактаў, якія характарызуюць новага карыстальніка сістэмы.
Па меры ўзаемадзеяння чалавека з сістэмай ён прадастаўляе ёй дадатковую інфармацыю пра сябе. Па меры набыцця гэтага
інфармацыі, сістэма можа паступова абнаўляць сваю мадэль карыстальніка, пакуль у рэшце рэшт яна не стане мадэллю гэтага
індывід у адрозненне ад карыстальніка- кананіка. Выкарыстоўваючы гэты падыход, найбольшыя намаганні будуць выдаткаваны на пабудова мадэляў частых карыстальнікаў, у той час як значна менш сіл будзе затрачана на мадэлі вельмі рэдкіх карыстальнікі, мадэлі, якія не маюць вялікай выгады ў агульным задавальненні карыстальнікаў.
Самы важны вынік выбару дазволіць сістэме стварыць уласную мадэль карыстальніка tJte, заснаваную на узаемадзеянне паміж імі заключаецца ў тым, што большая частка інфармацыі, якая змяшчаецца ў мадэлі, будзе здагадкамі. Такім чынам, сістэма
павінны мець нейкі спосаб адлюстравання таго, наколькі ён упэўнены ў кожным факце, акрамя спосабу вырашэння канфліктаў і абнаўленне мадэлі па меры з’яўлення новай інфармацыі. Раздзел 3 прапануе некалькі спосабаў зрабіць гэта.
2.3. Доўгатэрміновыя супраць кароткатэрміновых мадэляў
Абмяркоўваючы першыя два з гэтых трох вымярэнняў, можна было сцвярджаць, што адна з мадэляў карыстальніцкага мадэлявання будзе такой прывесці да больш прыдатнай для жыцця сістэмы, чым іншая. Пры абмеркаванні гэтага трэцяга вымярэння гэта ўжо не так. Па парадку каб разумна ўзаемадзейнічаць з карыстальнікам, сістэма павінна мець доступ да самай разнастайнай інфармацыі пра яго, пачынаючы ад шэрагу ад адносна доўгатэрміновых фактаў, такіх як узровень яго матэматычнай дасканаласці, да даволі кароткатэрміновых фактаў, напрыклад тэма апошняга сказа, які набраў карыстальнік. Нягледзячы на тое, што ўся гэтая інфармацыя можа спрыяць прыдатнасці а сістэмы, карысна, па меншай меры, на пачатку вывучэння тэмы мадэлявання карыстальнікаў, аддзяліць праблема высновы доўгатэрміновых мадэляў ад праблемы кароткатэрміновых мадэляў, таму што розныя метады могуцьпадыходзіць для вырашэння дзвюх праблем.
Верагодна, разумна патрабаваць, каб высілкі, выдаткаваныя на прыняцце рашэння аб тым ці іншым факце карыстальніка, былі
прыблізна прапарцыянальна часу, якое гэты факт зможа выкарыстаць. У адной крайнасці важна, каб яна была не здарыцца так шмат часу, каб паспрабаваць зрабіць выснову аб тым, што факт ужо не актуальны.У іншай крайнасці, можа быць разумным выдаткаваць шмат часу на шмат сеансаў, каб сфармаваць дакладную мадэль некаторых па сутнасці пастаянныя характарыстыкі.
Былі прыкладзены намаганні як для доўгатэрміновага, так і для кароткатэрміновага мадэлявання індывідуальных карыстальнікаў. Кароткачасовае мадэляванне мае важнае значэнне ў разуменні дыялога на прыроднай мове.
Разгледзім, напрыклад, наступны абмен:
Кліент:
Колькі каштуе білет у Нью-Ёрк?
Пісар:
Сто долараў.
Кліент: Калі наступны самалёт?
Пісар:
Наступны самалёт цалкам забраніраваны, але на гэтым яшчэ ёсць месца
сыходзіць у 8:04.
Кліент:
Добра, вазьму. гэта.
Для таго, каб зрабіць такі адказ, клерку прыйшлося звярнуцца да мадэлі бягучай мэты кліента – дабрацца да Нью-Ёрк. Было б недарэчным адказаць літаральна на пытанне і сказаць проста 6:53.
Калі камп’ютэрныя сістэмы збіраюцца выканаць заданне клерка ў гэтым прыкладзе, тады ім таксама трэба будзе мець магчымасць
будаваць і выкарыстоўваць мадэлі мэтаў сваіх арыстальнікаў. Але мадэлі такіх рэчаў, як бягучыя мэты, даволі кароткатэрміновыя
выкарыстоўваць. Той самы кліент можа з’явіцца заўтра, маючы намер сустрэцца з кім-небудзь з Нью-Ёрка і, такім чынам,
чакаючы іншага адказу. Такім чынам, для ўспрымання такіх мэтаў неабходна распрацаваць надзвычай аператыўныя метады
каб заўважыць, калі яны мяняюцца. Больш падрабязна абмеркаваць гэтыя віды пытанняў можна ў Perroult, Allen &
Коэн (1978) і Ман, Мур і Левін (1977).
Але многія сістэмы могуць карысна выкарыстоўваць вялікую колькасць значна больш стабільных ведаў пра сваіх карыстальнікаў. Гэтыя доўгатэрміновыя мадэлі могуць быць атрыманы на працягу шэрагу ўзаемадзеянняў паміж сістэмай і яе карыстальнікамі мадэлі могуць утрымліваць такую інфармацыю, як узровень дасведчанасці карыстальніка ў галіне камп’ютэрных сістэм у цэлым, яго вопыт з гэтай сістэмай, у прыватнасці, і яго знаёмства з асноўнай вобласцю задачы сістэмы. У дадатак да гэтых агульныя рэчы, якія могуць быць карыснымі ў самых розных сістэмах, карыстальніцкія мадэлі, якія выкарыстоўваюцца ў той ці іншай сістэме часта трэба будзе ўтрымліваць канкрэтную інфармацыю, якая мае дачыненне да сістэмы і яе задачы. Напрыклад, у Праграма бібліятэкара, якая будзе абмяркоўвацца ў раздзеле 4, кожная мадэль карыстальніка змяшчае інфармацыю пра такія рэчы, як перавага кнігам з хуткімі сюжэтамі і ўзроўнем талерантнасці да апісанняў гвалту.
2.4. АГЛЯД ПРАСТОРЫ
На малюнку 1 паказаны восем класаў мадэляў карыстальнікаў, створаных трыма дыхатаміямі, якія мы толькі што абмяркоўвалі
з некалькімі прыкладамі кожнага. У астатнім гэты артыкул будзе прысвечаны ніжнім правым куце.

Мал. 1. Прастора мадэляў карыстальнікаў.
3. Некаторыя метады пабудовы мадэляў карыстальнікаў
Вызначыўшы як неабходнасць мадэлявання карыстальнікаў, так і тыпы падыходаў, якія можна да яго выкарыстаць, некаторыя
зараз могуць быць прадстаўлены канкрэтныя метады, якія можна выкарыстоўваць для такога мадэлявання. У гэтым раздзеле іх шмат будуць разгледжаны метады:
- вызначэнне слоўнікавага запасу і паняццяў, якія выкарыстоўваюцца карыстальнікам.
- вымярэнне адказаў, якімі карыстальнік здаецца задаволеным.
- выкарыстанне стэрэатыпаў для стварэння мноства фактаў з некалькіх.
Гэтыя метады дзеляцца на дзве шырокія групы: метады для высновы асобных фактаў час і метады адначасовага вываду цэлых набораў фактаў. У наступных двух раздзелах разглядаюцца гэтыя два віды метады.
- ЗЛУЧАЮЧЫЯ ІНДЫВІДУАЛЬНЫЯ ФАКТЫ
Адзін з самых простых спосабаў атрымаць інфармацыю пра карыстальніка – паглядзець, як ён выкарыстоўвае сістэму. Той, хто пачынае сесію з серыі прасунутых каманд, напэўна, эксперт. Хтосьці, чые першыя некалькі спроб каманды адхіляюцца сістэмай, верагодна, пачатковец і мае патрэбу ў дапамозе. Просты спосаб рэалізацыі мадэляванне карыстальнікаў на аснове такога роду інфармацыі заключаецца ў стварэнні слоўніка сістэмных каманд, опцый і г.д. і звязаць з кожным элементам указанне, якую інфармацыю пра яго карыстальніка дае выкарыстанне гэтага элемента.
Гэтая інфармацыя можа быць розных вымярэнняў, такіх як экспертыза сістэмы і экспертыза сістэмы асноўная задача. Пасля атрымання гэтая інфармацыя можа быць выкарыстана для расшыфроўкі памылак карыстальніка і атрымання аведамленняў з патрэбным узроўнем апісання.
Іншы спосаб прадастаўляць інфармацыю пра сябе карыстальнікам – гэта шаблон іх каманд. Дапусцім, aкарыстальнік запытвае ў сістэмы пэўную інфармацыю.
Калі ён атрымае тое, што хоча, альбо сыдзе, альбо працягне
яго наступная просьба. Але калі ён не атрымае жаданага, ён, верагодна, паспрабуе перабудаваць сваю просьбу яшчэ адной спробай каб атрымаць тое, што ён хацеў. Гэта спроба павінна сігналізаваць сістэме, што яна не задаволіла патрэбнасць карыстальніка першай адказ.
Выкарыстанне абедзвюх гэтых методык можна праілюстраваць кароткім разглядам сістэмы, якой мы зараз займаемся будынак, інтэрактыўная даведка для сістэмы фарматавання дакументаў, Scribe (Рэйд, 1980). Карыстальнікі гэтай сістэмы можаце задаваць такія пытанні, як:
- Як мне атрымаць індэкс?
- Чаму палі такія шырокія?
- У чым розніца паміж камандай itemize і камандай enumerate?
Сістэма захоўвае свае веды пра Scribe як набор правілаў умоў і дзеянняў. У самым простым выглядзе гэтыя правілы ўтрымліваюць адну каманду Scribe як іх стан, і звязанае з гэтым дзеянне апісвае эфект, выраблены каманда. Аднак спосаб працы большасці каманд вызначаецца бягучымі значэннямі некаторай колькасці унутраныя зменныя сістэмы, таму іх таксама трэба згадаць як частку ўмоў правілаў. Гэта часта азначае, што некалькі правілаў, кожнае з розных умоў, усе апісваюць працу адной і той жа каманды Scribe апісанне працы сістэмы ў адпаведнасці з гэтымі правіламі з’яўляецца іерархічным. Дзеянні паказалі iri многіх правілы – гэта не прымітыўныя дзеянні, такія як размяшчэнне персанажа ў пэўным месцы на старонцы, а хутчэй вышэйшага ўзроўню дзеянні, часта іншыя каманды Scribe, эфекты якіх у сваю чаргу апісваюцца дадатковымі правіламі. Дзеянне кампанентам многіх правілаў з’яўляецца ўстаноўка нейкай сістэмнай зменнай, якая willlater ўплывае на працу іншых правілаў.
Гэтая іерархічная арганізацыя інфармацыі ў сістэме дазваляе сістэме адказваць пытанні на розных узроўнях дэталізацыі. Так, напрыклад, калі сістэме задаюць пытанне “чаму”, напрыклад “Чаму настолькі шырокія палі? “, ён можа адказаць альбо ўказаннем умоў, якія выклікалі ўзгаранне пэўнага правіла (напрыклад, “Значэнне lmarg складае 10, а значэнне rmarg – 10”), альбо ён можа вярнуцца да правілаў, каб вызначыць, як гэтыя ўмовы маглі б спраўдзіцца. Адпаведны ўзровень, на якім можна адказаць на пэўнае пытанне: функцыя ўзроўню самога пытання і ўзроўню ведаў карыстальніка, які задаваў пытанне. Для таго, каб каб вызначыцца з правільным узроўнем, сістэма падтрымлівае слоўнік, які змяшчае запіс па кожнай рэчы што можа сустракацца ў правілах – і як дзеянне, і як умова. З кожным запісам звязана інфармацыя, якая апісвае, калі можа быць мэтазгодна згадаць адпаведную канцэпцыю ў тлумачэнні.
Напрыклад, кожны канцэпцыя мае рэйтынг, які апісвае, наколькі эксперт павінен быць у Scribe, каб мець магчымасць зразумець
тлумачэнне з пункту гледжання гэтага. Такім чынам, многія з унутраных зменных сістэмы маюць вельмі высокі рэйтынг, у той час як просты карыстальнік каманды маюць вельмі нізкія. Кожная канцэпцыя таксама мае асобны рэйтынг, які апісвае ўзровень вытанчанасці з камп’ютэрнымі сістэмамі, неабходнымі для яго разумення. Напрыклад, уводныя файлы Scribe – гэта блокавыя структуры і Scribe апрацоўка іх ідзе па стандартнай мадэлі блочнай структуры. Праграміст, нават калі ён быў пачаткоўцам пісарам карыстальнік, зразумеў бы тлумачэнне ў гэтых выразах, у той час як больш дасканалая пішучая машыністка можа не зразумець.
Кожны раз, калі сістэма дапамогі спрабуе знайсці адказ на пытанне, яна спачатку знаходзіць правіла (або правілы), якія прымяняюцца да канкрэтнай сітуацыі. Тады ён разглядае паняцці, згаданыя ў гэтых правілах, і параўноўвае, што пра іх ведае да таго, што ён ведае пра карыстальніка, які задаваў пытанне. Калі ўзроўні супадаюць, адказ ствараецца неадкладна. Калі яны гэтага не робяць, сістэма злучае правілы, рухаючыся альбо ўверх, альбо ўніз па іерархіі, пакуль гэта не адбываецца знаходзіць тлумачэнне на правільным узроўні.
Зразумела, гэты метад мяркуе, што сістэма даведкі мае мадэль узроўню вытанчанасці карыстальніка. Як ці можна пабудаваць такую мадэль? На шчасце, той самы слоўнік паняццяў, які выкарыстоўваўся пры выкарыстанні мадэль таксама можа быць выкарыстана для яе пабудовы. Калі карыстальнік задае пытанне, ён фармулюе яго з пункту гледжання назіраных дзеянняў (такіх як як знакі на старонцы), каманды Scribe і параметры Scribe. Затым сістэма даведкі адпавядае гэтаму пытанне да асновы правілаў у спробе адказаць на яго. Для гэтага ён шукае кожны з элементаў пытання ў сваім слоўнік (які таксама служыць паказальнікам правілаў). Людзі часта спасылаюцца на паняцці, прасцейшыя за большасць складаныя, якія яны разумеюць, але яны не кажуць пра паняцці, больш складаныя, чым тыя, якія разумеюць. Такім чынам сістэма можа пачаць будаваць свае мадэлі новага карыстальніка, прымаючы значэнні, звязаныя з першымі канцэпцыямі згадвае. Калі пазней узгадаць больш складаныя канцэпцыі, можна ўзняць мадэль узроўню ведаў карыстальніка.
Мадэль карыстальніка таксама можа быць зменена, як было прапанавана вышэй, пры дапамозе шаблонаў пытанняў карыстальніка.
Дапусцім, сістэма няправільна ацэньвае ўзровень карыстальніка і адказвае на яго першае пытанне, спасылаючыся на параметр сістэмы, які нічога не значыць для карыстальніка. Наступнае пытанне карыстальніка амаль напэўна будзе спасылацца на гэты параметр у спробе разабрацца, што гэта значыць. Калі сістэма ўбачыць гэта, яна можа зрабіць выснову, што яе мадэль памылковая, а потым змяніць яе калі ён выяўляе ўзровень тлумачэння, якім карыстальнік задаволены. Аналагічна, калі сістэма недаацэньваеведанне карыстальніка, гэта дасць яму дастаткова шырокія, агульныя адказы, ён папросіць больш канкрэтную інфармацыю і пасля гэтага сістэма можа абнавіць сваю мадэль.
Такое мадэляванне карыстальнікаў вельмі простае. Гэта робіць, напэўна, неабгрунтаваным меркаванне, што існуе фіксаваны парадак, пры якім людзі даведаюцца пра сістэму. Хоць гэта меркаванне, верагодна, ілжывае, гэта не так зусім няправільна. Альтэрнатыўным падыходам было б стварэнне для кожнага карыстальніка падрабязнай мадэлі таго, што менавіта
ён ведае. Такі падыход неабходны ў сістэмах CAI, якія павінны кантраляваць навучальныя заняткі з такімі мадэлямі [гл., напрыклад, Self (1977)]. Але такі падыход вельмі дарагі, як з пункту гледжання часу, які патрэбен на пабудову
мадэлі і месца, якое патрабуецца для іх захоўвання для вялікай колькасці карыстальнікаў. Адносіны паміж карыстальнікам і сістэма значна больш свабодная ў кантэксце сістэмы дапамогі, чым у сістэме CAI. Карыстальнік захоўвае кантроль над
узаемадзеянне, і замест таго, каб выкарыстоўвацца ў канцэнтраваных сесіях для засваення ідэй, звычайна выкарыстоўваюцца сістэмы дапамогі эпізадычна вырашаць пэўныя праблемы. Такім чынам, патрэба ў дакладнай мадэлі ведаў карыстальніка менш жорсткая.
Хоць паміж гэтымі двума тыпамі сістэм, зразумела, няма дакладнай лініі, якая існуе, яна ўсё ж выглядае што ў многіх сітуацыях менш дасканалыя мадэлі карыстальнікаў могуць быць карыснымі для сістэмы дапамогі.
3.2. ВЫКАРЫСТАННЕ СТЭРЭАТЫПАЎ ДЛЯ ВЫПУСКА МНОГІХ РЭЧАЙ АДНАЧАС
Тэхнікі, якія абмяркоўваліся да гэтага часу, дазваляюць сістэме рабіць асобныя факты пра карыстальніка. Але калі карыстальнік
мадэль павінна быць вельмі складанай, пытанне аб тым, як сабраць усю неабходную інфармацыю ў разумны тэрмін часу ўзнікае. Магчыма, у карыстальніка будзе ўсяго некалькі развязак з сістэмай, таму для мадэлявання карыстальнікаў патрабуецца шмат узаемадзеянне для пабудовы пачатковай мадэлі будзе мала карысным. На шчасце, у многіх сітуацыях гэта можна назіраць
альбо невялікая колькасць фактаў, і з іх вывесці з дастатковай ступенню дакладнасці набор дадатковых фактаў. Чалавечы
прыкметы не размеркаваны цалкам выпадкова па ўсёй папуляцыі. Хутчэй яны часта сустракаюцца ў кластарах. Гэтыя кластары могуць узнікаць па розных прычынах, такіх як існаванне аднаго фактару, які выклікае некалькі прыкмет прысутнічае адразу альбо існуе прычынна-следчы ланцуг сярод саміх прыкмет. Напрыклад, чалавек заможны хутчэй за ўсё ездзіў больш, чым іншы чалавек, які вельмі дрэнна.
Людзі прадстаўляюць такія веды пра спадарожныя рысы ў сукупнасці стэрэатыпаў. Хоць слова стэрэатып мае. шмат негатыўных асацыяцый, важна абмежаваць яго выкарыстанне тут выключна апісальным пералік набору прыкмет, якія часта сустракаюцца разам. З гэтага пункту гледжання стэрэатып – гэта проста спосаб фіксуючы некаторыя структуры, якія існуюць у свеце вакол нас. З апошніх некалькіх дзесяцігоддзяў працы ў
штучнага інтэлекту, мы прыйшлі да разумення велічыні ведаў, неабходных для разваг пра свет. На шчасце, мы таксама выявілі, што гэтыя веды маюць вялікую структуру, якая, калі і можа быць
захоплены, значна абмяжоўвае тое, што неабходна разгледзець у любы момант. Напрыклад, падзей няма адбываюцца выпадкова. Замест гэтага распаўсюджаныя шаблоны падзей, такія як уваход у рэстаран, атрыманне меню, заказ, ёсць і плаціць. Гэтыя мадэлі падзей прывялі да распрацоўкі сцэнарыяў (Schank & Abelson,1977), якія апынуліся надзвычай карыснымі пры пабудове праграм для разумення апісанняў падзей такія, як тыя, што сустракаюцца ў газетных апавяданнях. Стэрэатыпы даюць падобную структуру інфармацыі пра людзей. Проста паколькі сцэнарыі карысныя для разважанняў пра падзеі, неабходныя для разумення газетных гісторый, стэрэатыпы карысныя для разважанняў пра людзей, неабходных для стварэння карыстальніцкіх мадэляў. У прыватнасці, янызабяспечыць спосаб фарміравання праўдападобных высноў пра яшчэ нябачаныя рэчы на аснове таго, што было назіраецца.
Стэрэатып уяўляе сабой сукупнасць рыс. Ён можа быць прадстаўлены ў выглядзе сукупнасці пар атрыбут-значэнне. Мы будзем назавіце кожны такі атрыбут фасеткай. Мадэль індывідуальнага карыстальніка таксама можа быць прадстаўлена ў выглядзе набору граняў, запоўненых значэнні. Грані стэрэатыпаў, якія выкарыстоўвае сістэма, павінны адпавядаць граням карыстальніцкіх мадэляў, пабудаваных сістэма. Напрыклад, адной з рыс, якую можа быць карысна разгледзець, з’яўляецца ўзровень досведу карыстальніка з пэўным сістэма. Такім чынам, мадэлі асобных карыстальнікаў, а таксама адпаведныя стэрэатыпы будуць утрымліваць аспект “экспертызы”, якія могуць прымаць значэнні, скажам, ад 1 да 10.
Некаторыя рысы могуць быць лёгка заўважныя. Яны служаць трыгерамі, якія выклікаюць актывацыю ўсяго стэрэатыпу.
Паколькі наяўнасць рысы можа наводзіць толькі на пэўны стэрэатып, а не на абсалютнае яго сведчанне, кожны трыгер звязаў з ім рэйтынг, які з’яўляецца грубай мерай верагоднасці таго, што стэрэатып ёсць падыходзіць, улічваючы, што спускавы механізм назіраўся. Зразумела, справа не толькі ў залежнасці паміж трыгерамі і стэрэатыпы, што ў лепшым выпадку мяркуе. Стэрэатып кажа толькі пра тое, што набор рыс часта сустракаецца разам, а не тое яны заўсёды робяць. Такім чынам, з кожным аспектам стэрэатыпу звязаны рэйтынг, які ацэньвае верагоднасць адпаведная рыса з улікам адпаведнасці стэрэатыпу.
Стэрэатыпы ўяўляюць структуру сярод прыкмет.Часта існуе дадатковая структура, якую можна захапіць прадстаўляючы сукупнасць стэрэатыпаў як іерархію. Інфармацыя ў вельмі агульных стэрэатыпах можа выкарыстоўвацца хіба што супярэчлівая інфармацыя падказваецца больш канкрэтнымі стэрэатыпамі. Самы агульны стэрэатып, даступны для сістэмы можа прадстаўляць мадэль кананічнага карыстальніка. Такім чынам, нават без вялікай колькасці інфармацыі, сістэма, пабудаваная на стэрэатыпах, будзе зрабіць не горш, чым той, які пабудаваны на традыцыйнай убудаванай мадэлі кананічнага карыстальніка.
Адна з найбольш важных праблем, якую трэба вырашыць у любой сістэме мадэлявання карыстальнікаў на аснове высноў з паводзіны карыстальніка – гэта спосаб выяўлення і ўрэгулявання канфліктаў паміж высновамі. Каб палегчыць гэта, рэйтынгі ёсць прымацоўваецца як да трыгераў, так і да кожнага прагнозу (аспекту) кожнага стэрэатыпа. Акрамя таго, кожная грань чалавека мадэль карыстальніка павінна ўтрымліваць не толькі значэнне, але і ацэнку ўпэўненасці сістэмы ў гэтым значэнні (якое можа быць выкарыстоўваецца для вызначэння, наколькі значэнне павінна мець уплыў на эфектыўнасць агульнай сістэмы) і а спіс прычын, па якіх вераць у каштоўнасць. Гэты спіс прычын важны. Напрыклад, выкажам здагадку, што стэрэатып
актывуецца ў выніку назіранай рысы карыстальніка. Гэты стэрэатып прадказвае значэнне для пэўнай грані, але мадэль карыстальніка сістэмы ўжо ўтрымлівае іншае значэнне для гэтага аспекта. Калі б сістэма запомніла, адкуль яна гэта значэнне ад, магчыма, можна даволі лёгка вырашыць канфлікт, як, напрыклад, калі пайшло ранейшае значэнне стэрэатып, больш агульны, чым той, які толькі актывуецца.
Часам некалькі розных стэрэатыпаў могуць прадказваць адно і тое ж значэнне, а не розныя для грані. У гэтым У гэтым выпадку ўзровень даверу сістэмы да прагназавання можа быць вышэйшы, чым калі б толькі адна крыніца інфармацыя прысутнічала. Паколькі разумна для стэрэатыпаў прадказваць іншыя стэрэатыпы, а для пэўных аспектаў – пары значэнняў для прагназавання стэрэатыпаў, прыток новай інфармацыі можа запатрабаваць распаўсюджвання рэйтынгавых змяненняў на працягу карыстацкай мадэлі. Дакладна, наколькі эфектыўна працягваць такое размнажэнне, – гэта пытанне трэба вызначыць эмпірычна.
Усе гэтыя метады спалучэння высноў, прапанаваных рознымі стэрэатыпамі, можна абагульніць, каб сфармаваць аснова для інтэграцыі самых розных крыніц ведаў пра асобнага карыстальніка. Карысна, наколькі могуць быць стэрэатыпы дазваляючы пачатковую канструкцыю карыстацкай мадэлі даволі хутка, яны не ліквідуюць неабходнасць у іншых відах інфармацыя, уключаючы як адказы на прамыя пытанні, так і іншыя ўскосныя прыёмы, разгледжаныя вышэй у кантэкст памочніка Scribe. Але адзін раз кожны элемент карыстацкай мадэлі суправаджаецца рэйтынгам і спісам пацвярджаючы гэта, лёгка дадаць адвольныя крыніцы ведаў. Новая інфармацыя, якая падтрымлівае старыя каштоўнасці выклікае павелічэнне рэйтынгаў, прывязаных да значэнняў. Новая інфармацыя, якая канфліктуе са старымі каштоўнасцямі, выклікае развязвальнік канфліктаў, каб вывучыць давер да канкуруючых галасоў, каб даць такую ж ацэнку ісціны магчыма. Адказы карыстальніка на прамыя пытанні могуць мець перавагу над простымі высновамі, якія, у сваю чаргу, могуць быць надаецца прыярытэт перад прагнозамі стэрэатыпаў.
Да гэтага часу абмеркаванне выкарыстання стэрэатыпаў было агульным і пазбягала спасылак на пэўныя сістэмы альбо дамены заданняў. У наступным раздзеле – канкрэтная сістэма, якая паспяхова выкарыстоўвала стэрэатыпы для стварэння мадэляў сваіх карыстальнікаў будзе абмяркоўвацца. Агульныя пункты, згаданыя ў гэтым раздзеле, будуць праілюстраваны на канкрэтных прыкладах.
4. Грандзі: тэматычнае даследаванне па выкарыстанні стэрэатыпаў
Для таго, каб праверыць многія з выкладзеных вышэй ідэй, была пабудавана пілотная сістэма пад назвай Grundy. Грундзі рэкамендуе раманы, якія людзі, магчыма, хацелі б прачытаць. Для гэтага ён выкарыстоўвае дзве калекцыі дадзеных:
- апісанні асобных кніг.Кожнае апісанне ўяўляе сабой набор граняў, запоўненых адпаведнымі значэннямі.
- стэрэатыпы, якія ўтрымліваюць грані, якія адносяцца да густу людзей у кнігах.З кожным стэрэатыпам звязана а збор трыгераў.
Акрамя таго, Грандзі мае пэўныя веды пра кожны з аспектаў, якія могуць узнікнуць у стэрэатыпах. Гэтыя веды выкарыстоўваецца для ўрэгулявання канфліктаў паміж канкуруючымі высновамі, а таксама для супастаўлення інфармацыі ў карыстальніку мадэль інфармацыі ў апісаннях кніг. Для апісання Грундзі больш поўнае, чым прадстаўленае тут гл. Rich (1979a, b).
Калі новы карыстальнік пачынае размову з Грэндзі, яму прапануецца даць некалькі слоў, якія ён думае забяспечыць добрае самаапісанне. Грундзі выкарыстоўвае гэтыя словы як трыгеры для стварэння адпаведных стэрэатыпаў, і ўсё пачынаецца пабудова сваёй мадэлі карыстальніка. Звычайна ў гэты момант актывізуецца некалькі стэрэатыпаў, і часта ўзнікаюць канфлікты сярод іх прагнозаў, якія Грандзі вырашае як мага лепш. Затым Грундзі ацэньвае (выкарыстоўваючы камбінацыю колькасць рэчаў, у якія ён верыць, і наколькі моцна ім верыць), ці дастаткова ў яго інфармацыі для пачатку
рэкамендацыя кніг. Калі так, то гэта ідзе наперад. Калі гэтага не адбываецца, ён просіць у карыстальніка яшчэ некалькі слоў.
На малюнку 2 паказаны два стэрэатыпы, якія выкарыстоўваў Грундзі. На малюнку 3 паказана, як будзе выглядаць мадэль карыстальніка Грундзі як пасля таго, як сказалі імя карыстальніка (і вывелі з яго, што яна жанчына), і пасля таго, як спецыяльна актывавалі Жанчыны, феміністычныя і інтэлектуальныя стэрэатыпы. Кожны раз, калі Грандзі актывуе стэрэатып, ён таксама актывуе усе абагульненні гэтага стэрэатыпа, таму стэрэатыпы АДУКАВАНАЯ АСОБА і ЛЮБЫ АСОБА (кананічны мадэль карыстальніка) таксама былі актываваны. Звярніце ўвагу, што кожны са стэрэатыпаў утрымлівае толькі некаторыя аспекты змяшчаецца ў поўнай карыстальніцкай мадэлі. Гэта часта адбываецца, бо многія стэрэатыпы ўключаюць у сябе толькі адзін (ці, магчыма, некалькі) значныя аспекты чалавека.
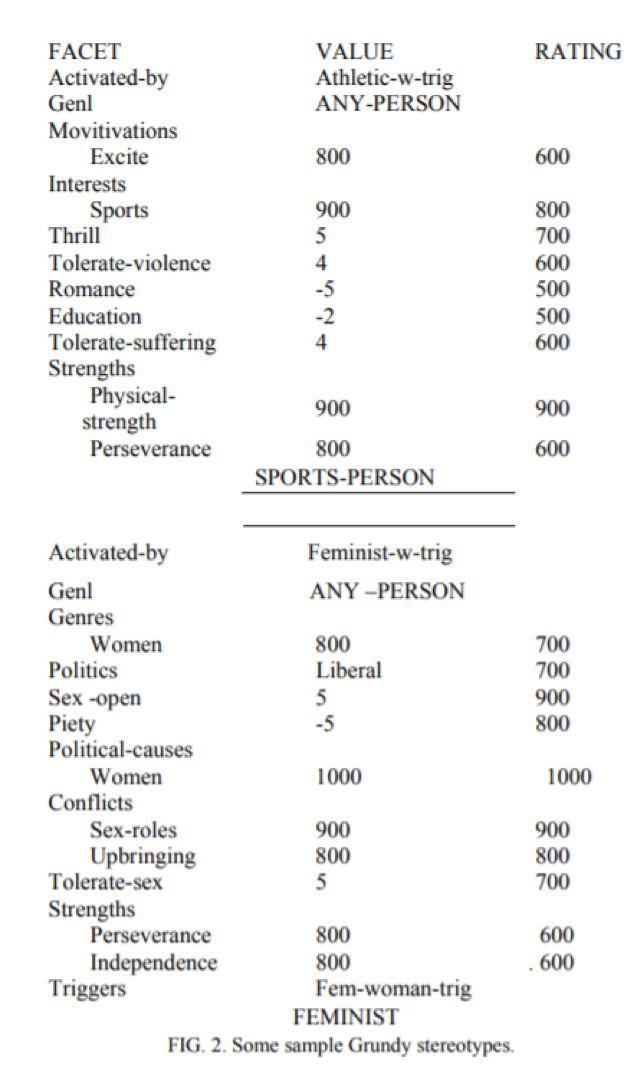
Мал. 2. Некаторыя ўзоры стэрэатыпаў Грундзі.
Пасля назапашвання дастатковай колькасці інфармацыі Грандзі пачынае рэкамендаваць кнігі па чарзе карыстальнік кажа яму спыніцца. Працэс выбару кнігі працякае наступным чынам.
- Абярыце прыкметную грань у карыстацкай мадэлі. Яркія аспекты – гэта тыя, у якіх значэнні не сярэднія і высокія рэйтынгі.
- Выкарыстоўвайце інвертаваны індэкс у базе дадзеных кніг, каб выбраць усе кнігі, прапанаваныя гэтым канкрэтным аспектам.
- Параўнайце кожную з выбраных кніг з мадэллю карыстальніка па ўсіх вымярэннях. Выключыце кнігі, якія перавышаюць пэўныя
парогі (напрыклад, памяркоўнасць да гвалту).
- З кніг, якія не былі ліквідаваны, выберыце тую, якая найбольш адпавядае. Калі гэта вышэй за парог блізкасць супадзення, рэкамендуйце. У адваротным выпадку перайдзіце да кроку 1, абярыце новую грань і паўтарыце спробу Мал. 2.
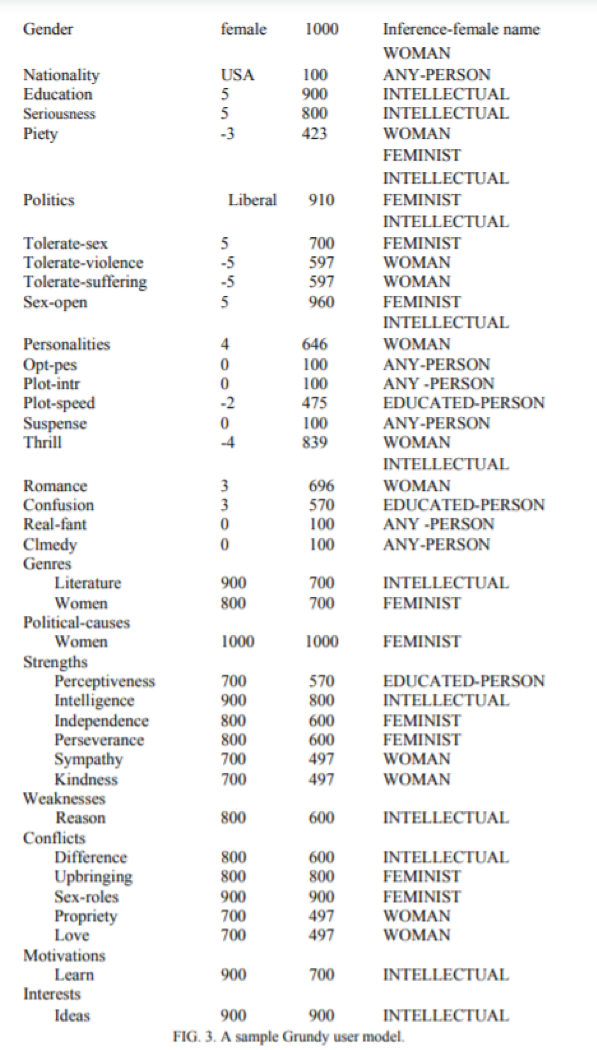
Мал.3. Прыклад мадэлі карыстальніка Grundy.
Выбраўшы кнігу, Грандзі паведамляе карыстальніку імя і імя аўтара і запытвае яе, ці ёсць у яе чытайце яго раней. Калі яна мае, Грандзі ведае, што гэта на правільным шляху. Цяпер яна можа ўмацаваць сваю веру ў тое, што прывяло яго да выбару гэтай кнігі. (Гл. Раздзел 5 для дадатковага абмеркавання пытання аб мадыфікацыі базы дадзеных Грандзі.) Калі яна не спадабалася кніга, Грандзі трэба высветліць, чаму. У ідэале было б проста сказаць: “Чаму б і не?”, Але значна больш для тлумачэння адказаў на такое пытанне спатрэбяцца веды, чым у Грандзі. Напрыклад, хтосьці можа кажуць, што кніга ёй не спадабалася, бо галоўны герой нагадаў ёй пра свайго стаматолага. Таму замест гэтага Грандзі спрабуе высветліць, якое з меркаванняў пра карыстальніка і пра тое, што раней ён выбіраў гэтую кнігу, было памылковым. Каб зрабіць гэта, гэта задае некалькі прамых пытанняў, пакуль альбо не выявіць праблему, альбо прымусіць адмовіцца. Калі праблема была знойдзена, значыць можа абнаўляць як мадэль карыстальніка, так і базу дадзеных стэрэатыпаў.
Калі карыстальнік кажа Грундзі, што яна не чытала кнігу, Грундзі кажа ёй некаторыя рэчы, якія, на яго думку, цікавяць ёй пра гэта. Грундзі выкарыстоўвае мадэль карыстальніка, каб выбраць, якую характарыстыку кнігі згадаць. Потым пытаецца карыстальнік, ці думае яна, што ёй спадабаецца кніга. На гэты раз, калі яна скажа “так”, Грандзі нічога не робіць, так як станоўчы адказ заснаваны толькі на некалькіх фактах, якія карыстальнік бачыў. Але калі карыстальнік кажа, што кніга не выглядае цікава, Grundy выкарыстоўвае апісаную вышэй працэдуру, каб паспрабаваць высветліць, што пайшло не так, каб паспрабаваць знайсці
нешта ёй спадабаецца больш.
Для таго, каб праверыць карыснасць карыстацкіх мадэляў Grundy, быў праведзены эксперымент, у рамках якога Grundy даваў кожную карыстальнікаў колькі заўгодна прапаноў. Гэта таксама дало ім кожнаму некалькі прапаноў, выбраных выпадковым чынам без дапамогі карыстацкай мадэлі і спытаў у іх, ці добра выглядаюць прапановы. Яны служылі кантролем.
У табліцы 1 паказаны працэнт прапаноў, якія былі апісаны як добрыя, у адрозненне ад тых, якія апісаны як дрэнныя, абодва у кантраляваным рэжыме (дзе мадэль карыстальніка вызначала выбар) і ў выпадковым рэжыме. Гэтыя лічбы гэта паказваюць
Grundy значна лепш (p <lO-9) лепш з мадэллю карыстальніка, чым без яе.
Хаця мадэлі карыстальнікаў Grundy не набліжаюцца да таго, каб захапіць аніякія складана звязаныя фактары вызначыць, якія раманы спадабаюцца чалавеку, узровень паспяховасці прапаноў указвае на тое, што ён менш чым завершаны карыстальніцкія мадэлі могуць даць карысныя рэкамендацыі інтэрактыўным сістэмам.
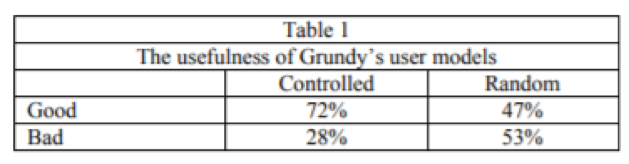
Табліца 1.
Карыснасць карыстацкіх мадэляў Grundy
5. Навучанне ў Грунды
Стэрэатыпы вельмі карысныя, каб дазволіць сістэме хутка стварыць пачатковую мадэль новага карыстальніка, каб яна магла займіцеся любой рэальнай задачай. Але як мы можам выпрацаваць дакладныя стэрэатыпы для выкарыстання сістэмы? Будзе ўсё намаганні па мадэляванні карыстальнікаў будуць марнымі, калі стэрэатыпы недакладныя? Гэта важныя пытанні, якія яшчэ патрэбны поўныя адказы, але досвед працы з Грандзі мяркуе, што яны не ўяўляюць сабой непераадольных перашкод.
Першапачатковыя стэрэатыпы Грандзі прадстаўлялі толькі маю інтуіцыю пра людзей і кнігі, якія яны чыталі. Ніякай спробы не было зроблены для збору цвёрдых дадзеных. Нягледзячы на гэта, стэрэатыпы вельмі карысныя. Але больш цікавае, што можа быць
заўважана, што Грандзі здольны мадыфікаваць свае стэрэатыпы на аснове свайго досведу, калі гэты вопыт супярэчыць прагнозам стэрэатыпаў. Могуць быць зроблены толькі даволі простыя мадыфікацыі. Нельга дадаць грані альбо выдалены, але значэнне грані можа змяняцца, як і яе рэйтынг.
Першапачатковы стэрэатып Грандзі для тыповага чытача- мужчыны паказваў, што мужчыны любяць чытаць кнігі з хуткаплыннымі сюжэтамі і шмат хваляванняў і хваляванняў. Гэта можа тычыцца мужчынскага насельніцтва ЗША, а вось мужчын Грандзі на самай справе піла была не вельмі шырокім перасекам гэтай папуляцыі; усе яны былі выкладчыкамі і выпускнікамі універсітэта студэнты. Такім чынам, ім падабаліся інтэлектуальныя віды кніг, якія, як правіла, больш моцныя па філасофіі, чым па сюжэце. Такім чынам Грундзі паступова змяніў свой стэрэатып MAN, каб адлюстраваць густы насельніцтва мужчын, якіх ён бачыў чым некаторае насельніцтва, якое я сабе ўяўляў. Той факт, што ён мог бы гэта зрабіць, сведчыць пра дзве абнадзейлівыя рэчы па сутнасці справы выкарыстання стэрэатыпаў у сістэмах мадэлявання карыстальнікаў:
- не крытычна важна, каб былі створаны дакладныя дадзеныя, якія апісваюць карыстальніцкае супольнасць, для стварэння пачатковага набору стэрэатыпы.
- калі ў розных супольнасцях выкарыстоўваецца адзіная сістэма, яе стэрэатыпы могуць развівацца асобна ў кожнай з іх што кожны з іх характарызуецца дастаткова дакладна.
Зразумела, магчымыя і іншыя віды навучання, якіх Грундзі не робіць. Grundystores захоўвае ўсе свае карыстальніцкія мадэлі што калі карыстальнік вяртаецца для наступных сеансаў, новую мадэль не трэба будаваць з нуля. Такім чынам можна было б будаваць цалкам новыя стэрэатыпы, назіраючы шаблоны рысаў, якія часта сустракаюцца ў карыстальнікаў.
6. Выснова
У гэтым артыкуле я сцвярджаў, што для многіх інтэрактыўных камп’ютэрных сістэм карыстальнікаў дастаткова неаднародна, што адна мадэль кананічнага tіser неадэкватная. Замест гэтага магчымасць фарміравання індывідуальных мадэляў індывідуальных карыстальнікаў. І тады я паказаў, што, акрамя неабходнасці, магчымыя і такія мадэлі, і прадстаўлена калекцыя спосабаў іх пабудовы і выкарыстання.
Агульнае для ўсіх гэтых метадаў заключаецца ў тым, што яны ўключаюць здагадкі пра карыстальніка. Гэтыя здагадкі ёсць зроблены сістэмай на аснове яе ўзаемадзеяння з карыстальнікам. У выніку верагоднасць памылкі павінна быць заўсёды разглядаецца. Каб справіцца з гэтым, сістэма павінна зрабіць дзве рэчы:
- ён павінен прымацаваць рэйтынгі і абгрунтаванні да кожнай рэчы, у якую лічыць.
- яна не павінна разглядаць мадэль карыстальніка як выпраўленую, а як нешта, на чым яна можа пастаянна ўдасканальвацца шляхам збору зваротнай сувязі з карыстальнікам аб кожным узаемадзеянні.
Спіс літаратуры
CARD, SK, MORAN, TP & NEWELL, A. (1980). Мадэль на ўзроўні націску клавіш для часу працы карыстальніка
інтэрактыўныя сістэмы. Паведамленні Асацыяцыі вылічальных машын, 23, 396-410.
CODD, EF (1974). Сем крокаў да спаткання з выпадковым карыстальнікам. У KLIMBIE, JW & KOFFEMAN, KL,
Выдання, кіраванне базай дадзеных. Амстэрдам: Паўночная Галандыя.
КАФФ, Р. Н. (1980). На выпадковых карыстальніках. Міжнародны часопіс даследаванняў чалавек-машына, 12, 163-187.
FITTS, PM & PETERSON, J. R (1964). Інфармацыйная ёмістасць дыскрэтных рухальных рэакцый. Часопіс
Эксперыментальная псіхалогія, 67, 103-112.
ГЕНЭСЕРЕТ, М. (1978). Аўтаматызаваны кансультант карыстальніка для MACSYMA. Кандыдат навук дысертацыя, Гарвардскі універсітэт.
Хадженс, Джорджыя і Білінгслі, Пенсільванія (1978). Сэкс: адсутнічае зменная ў даследаваннях чалавечага фактару. Чалавечы Фактары, 20, 245-250.
LEDGARD, H., WHITESIDE, JA, SINGER, A. & SEYMOUR, W. (1980). Натуральная мова інтэрактыву сістэмы. Паведамленні Асацыяцыі вылічальных машын, 23, 556-563.
LOO, R (1978). Індывідуальныя адрозненні і ўспрыманне дарожных знакаў. Чалавечыя фактары, 20, 65-74.
MANN, WC, MOORE, JA & LEVIN, JA (1977).
Мадэль разумення чалавечага дыялогу. У
Матэрыялы Міжнародная сумесная канферэнцыя “Штучны інтэлект”, 5, 77-87.
MCGUIRE, WJ & PADAWER-SINGER, A. (1976). Адметнасць прыкмет у спантаннай Я-канцэпцыі. Часопіс
Асоба і сацыяльная псіхалогія, 33, 743-754.
MITTMAN, B. & BORMAN, L. (1975). Персаналізаваныя сістэмы баз дадзеных. Лос-Анджэлес: Melville Publishing Co.
NISBETT, R E. & WILSON, TD (1977). Кажуць больш, чым мы можам ведаць: вусныя паведамленні пра псіхічныя працэсы.
Псіхалагічны агляд, 84, 231-259.
PERRAULT, C. R, ALLEN, JF & COHEN, P. R (1978). Маўленне выступае асновай для разумення дыялогу звязнасць. У матэрыялах другой канферэнцыі па тэарэтычных пытаннях натуральнай мовы Апрацоўка.
РЭЙД, БК (1980). Scribe: мова спецыфікацыі дакумента і яго кампілятар. Кандыдат навук дысертацыя, Карнегі-Мелон
Універсітэт.
РЫЧ, Э.А. (1979а). Стварэнне і выкарыстанне мадэляў карыстальнікаў. ‘Кандыдат навук дысертацыя, Універсітэт Карнегі-Мелона.
РЫЧ , Э.А. (1979b). Мадэляванне карыстальнікаў праз стэрэатыпы. Кагнітыўная навука, 3, 329-354.
Робертсан, Г., Ньюэл, А. і Рамакрышна, К. (1981). Падыход ZOG да чалавека-машыны зносіны. Унутраны часопіс даследаванняў чалавека і машыны, 14 (4), 461-488.
ШАНК, Р. С & АБЕЛЬСБН, Р П. (1977). Мэты, планы, сцэнарыі і разуменне: даследаванне чалавека Структуры ведаў. Хілсдэйл, штат Нью-Джэрсі: Erlbaum Press.
САМ, JA (1977). Канцэпцыя выкладання. Штучны інтэлект, 9, 197-221.
СМІТ, С. (1979). Памер ліста і разборлівасць. Чалавечыя фактары, 21, 661-670.
ф