Int. J. Человеко-машинные исследования (1983) 18, 199-214
Пользователи – это личности:
– индивидуализация моделей пользователей
ЭЛЕЙН РИЧ
Департамент компьютерных наук, Техасский университет в Остине, Остин, Техас 78712, США
(Поступила 13 мая 1981 г.)
Давно признано, что для создания хорошей системы, в которой человек и машина взаимодействуют при выполнении задачи, важно учитывать некоторые значимые характеристики людей. Эти характеристики
используются для построения некой «пользовательской модели».Традиционно построенная модель представляет собой модель канонической (или типичный) пользователь. Но часто отдельные пользователи так сильно различаются, что модели канонического пользователя недостаточно. Вместо, необходимы модели индивидуальных пользователей. В этой статье представлены несколько примеров ситуаций, в которых отдельные модели пользователей важны. Также представлены некоторые приёмы, позволяющие создавать и использовать такие модели возможными. Все эти методы отражают желание переложить большую часть бремени построения моделей на систему, а не на пользователя. Это приводит к разработке моделей, которые представляют собой набор хороших догадок о пользователе. Таким образом, необходимо какое-то вероятностное рассуждение.И, поскольку, модели используются для руководства лежащего в основе системы, они также должны отслеживаться и обновляться в соответствии с взаимодействиями между пользователем и
системой. Обсуждается производительность одной системы, в которой используются некоторые из этих методов.
1. Введение
Давно признано, что для создания хорошей системы, в которой человек и машина взаимодействуют, при выполнении задачи важно учитывать некоторые значимые характеристики людей. Затем система может быть предназначены для использования этих характеристик, а не для борьбы с ними.
Традиционно это делалось путём сбора данных об эффективности среднего человека при выполнении различных задач в различных средах. Например, закон Фиттса (Fitts & Peterson, 1964) гласит, что время, необходимое человеку, чтобы переместить объект в руке в определённую целевую позицию пропорционально log 2 (2A / w), где A – расстояние, на которое нужно переместить, а w – ширина цели. Этот результат показывает, как скорость, с которой человек может управлять машину можно увеличить, увеличив размер мишеней (таких как кнопки и переключатели), которые оператор должен ударить. В качестве ещё одного примера работы этого класса рассмотрим большой объем данных о взаимосвязи между размером букв и их читаемостью (Smith, 1979). Эти результаты важны при проектировании не только самых разнообразных машин, но также и других артефактов, таких как дорожные знаки.
Основная слабость этих исследований заключается в том, что они делают предположение, что вовлечённые люди составляют однородный набор. Согласно этому предположению, значения, которые определены для характеристики “типичного” человека, могут быть
использованы для разработки системы, которая будет использоваться всеми остальными. Хотя в большинстве случаев верно, что по крайней мере для большинства людей, система адаптирована к ним лучше, чем она была бы без этих исследований, неверно, что такая система, вероятно, будет лучшей из возможных. Намного лучше была бы система, в которой интерфейс
представленный каждому человеку был бы адаптирован к его собственным характеристикам, а не к характеристикам каких-то абстрактных “типичных” людей. Хотя обсуждение индивидуальных различий между пользователями редко в литературе встречается по человеческому фактору, они не совсем отсутствует. Например, Hudgens & Billingsley (1978) утверждают, что пол является важной переменной человеческого
факторы исследования. Другое исследование, проведённое Лоо (1978), обсуждает индивидуальные различия в восприятии дорожных знаков.
Одна из причин того, что такие исследования были редкостью, заключается в том, что они часто слишком дороги или невозможны по физическому обустройству – высокий уровень гибкости, который они предлагают. Однако по мере того, как мы начинаем видеть, что все больше и больше людей взаимодействия с машинами, опосредованные компьютерами под управлением программного обеспечения, становится возможным обеспечить гибкость, необходимая для действительно персонализированных систем.
В качестве простого примера снова рассмотрим вопрос размера букв и их разборчивости. Если это буквы дисплея
воспроизведённые с использованием стандартного светодиодного дисплея, то они будут одинакового размера для всех считывателей. Но предположим, что буквы отображается на ЭЛТ, управляемом компьютером. Теперь линии можно рисовать везде, где необходимо, чтобы получить широкие различные размеры букв по запросу отдельных пользователей.
В последнее время дизайнеры пользовательско – компьютерных интерфейсов начали обращать внимание на потребности определенных типов пользователей. Одна из часто обсуждаемых групп – это класс “случайных” пользователей, от которых нельзя ожидать, что они используют систему с большой регулярностью [см., например, Codd (1974) и Cuff (1980)]. Затем эта группа должна быть в отличие от менее изученных видов, обычных, опытных пользователей. К сожалению, немногие системы будут используется исключительно людьми одного класса. И похоже, что системные функции, облегчающие жизнь одному типу пользователь усложняет задачу для другого. Например, одно исследование эффективности пользователей – экспертов в задаче редактирования текста (Card, Moran & Newell, 1980) предполагает, что количество нажатий клавиш, необходимое для выполнения операция должна быть минимизирована. Ещё одно исследование людей, которые только учатся пользоваться редактором (Ledgard, Whiteside, Singer & Seymour, 1980) предлагает использовать полные слова на английском языке. Эти противоречивые требования указывают на необходимость в системе, которая может различаться для разных пользователей.
К счастью, компьютер предоставляет средства для повышения персонализации, так как он также даёт больше потребность в этом, увеличивая круг задач, для решения которых люди могут надеяться получить прибыль, имея дело с машинами. Задачи, которые
ранее выполнялись людьми, например, сбор желаемой информации из какой-то базы данных, теперь делаются компьютерами. Люди, которые выполняли эти задачи, смогли удовлетворить разнообразные потребности другие люди, с которыми они имели дело. Чтобы машины могли выполнять эти задачи и выполнять их удовлетворительно, они тоже будут должны быть способны приспособиться к индивидуальным потребностям. Для этого им придётся использовать модели отдельных пользователей, с которыми они сталкиваются. Это потребует расширения традиционного понятия «пользовательская модель».
В оставшейся части этой статьи мы исследуем проблему пользовательского моделирования конкретно в контексте компьютерного моделирования программных систем, как из-за все более широкого использования таких систем большими группами людей, так и из-за присущим таким системам гибкости, которая делает возможным эффективное моделирование.
2. Пространство пользовательских моделей
Термин «пользовательская модель» можно использовать для описания самых разных знаний о людях. Использование пользовательских моделей охватывают домен одинаковой ширины. Отношения между этими разнообразными структурами можно довольно легко увидеть, если Вселенная «пользовательских моделей» характеризуется как трёхмерное пространство. Размеры, каждого из которых будет рассматриваться ниже более подробно:
- одна модель одного канонического пользователя против набора моделей отдельных пользователей.
- модели, указанные явно либо разработчиком системы, либо самими пользователями, по сравнению с моделями, выведенными система на основе поведения пользователей.
- модели с довольно долгосрочными пользовательскими характеристиками, такими как области интересов или опыт, по сравнению с моделями относительно с краткосрочными характеристиками пользователя, такие как проблема, которую пользователь в настоящее время пытается решить.
Есть и другие существенные различия между системами, использующими эти различные типы пользовательских моделей, но они следуют из этих основных различий. Системы с единственной моделью канонического пользователя могут иметь эту модель, что постоянно встроена в самих себя, тогда как системы с моделями отдельных пользователей должны строить модель
“ на лету ”, и поэтому необходимо четко указать, каким образом модель влияет на производительность всей системы.
Системы, которые извлекают модель пользователя из поведения пользователя, должны серьёзно решать проблемы неправильной или противоречивой информации, вытекающей из выводов, которые привели к данной модели. Системы с явно указанным пользователем
информацией могут, с другой стороны, избежать многих из этих проблем. Системы, работающие с краткосрочными знаниями, должны успешно справляются с проблемой обнаружения, когда что-то меняется, в то время как более долгосрочные системы могут проявлять ловкость в этом вопросе. Но поскольку эти различия сводятся к трём, указанным выше, их не нужно сосредотачивать на явных мелких несоответствиях.
В следующих трёх разделах кратко обсуждается, как можно выбрать наилучшее положение в этом трехмерном пространстве.
2.1.КАНОНИЧЕСКИЕ МОДЕЛИ ПРОТИВ ИНДИВИДУАЛЬНЫХ МОДЕЛЕЙ
Этот параметр характеризует основное отличие “классической” работы с человеческим фактором от более гибкой модели, необходимые для предоставления индивидуализированных интерфейсов, которые позволяет программное управление. Разнообразие компьютерных систем были разработаны на основе канонической пользовательской модели. Например, ZOG (Робертсон, Ньюэлл и Рамакришна, 1981) – это
основанная на кадрах система, которая упрощает взаимодействие пользователя с компьютером. На его дизайн сильно повлияли такие факторы, такие как скорость отклика, необходимая для предотвращения разочарования пользователя. Еще один пример системы, построенной на модель канонического пользователя – это автоматизированный консультант Genesereth по MACSYMA, пакету символьной математики (Genesereth, 1978). Консультант использует явную модель стратегии решения проблем, используемую MACSYMA пользователями. Но, как было предложено выше, есть предел полезности этих канонических моделей для системы с гетерогенным сообществом пользователей. Отдельные модели могут позволить таким системам предоставить каждому пользователю более удобный интерфейс соответствующий его потребностям, чем можно было бы представить с помощью канонической модели. Конечно, необходимо продемонстрировать
что существуют методы для реализации таких моделей, чтобы они действительно улучшали производительность
системы. Разнообразие таких техник будет представлено в разделе 3.
Решение использовать отдельные пользовательские модели оказывает глубокое влияние на другие аспекты пользовательского моделирования. Если
система имеет только одну модель канонического пользователя, которую можно спроектировать один раз, а затем напрямую включены в общую структуру системы. Если, с другой стороны, система в конечном итоге должна обладать большим массивом моделей, соответствующих каждому из его пользователей, вопрос о том, как и кем эти модели должны быть построены возникает. Это приводит ко второму измерению в пространстве пользовательских моделей.
2.2. ЯВНЫЕ ПРОТИВ НЕЯВНЫХ МОДЕЛЕЙ
Есть два способа сделать системы разными для разных пользователей. Один из них – позволить пользователям модифицировать систему в соответствии под самих себя. Это подход, используемый многими системами, которые позволяют пользователям явно создавать свои собственные среды внутри системы.
Рассмотрим, например, компьютерную программу, которая позволяет пользователям системы общаться с каждым другим, отправляя почтовые сообщения туда и обратно. Программа хранит сообщения в наборе файлов и предоставляет функции, с помощью которых пользователи могут читать сообщения, отвечать на них и т. д. Такие системы часто позволяют пользователям устанавливать системные параметры, определяющие, например, какие поля сообщения будут отображаться при печати сообщения. А гораздо большая степень персонализации обеспечивается такими системами, как большинство реализаций программирования язык LISP, который позволяет пользователям указывать произвольно сложную программу, которая будет автоматически выполняться всякий раз, когда пользователь входит в систему. С помощью этого средства пользователь может создавать свои собственные процедуры, изменять системные переменные, или определить свои собственные символы. Такой же подход можно увидеть во многих системах «персонализированных баз данных» (Mittman &
Борман, 1975). В этих системах персонализация обусловлена тем, что каждый пользователь может явно выбрать интересующие его документы и информации, и хранить их в частной базе данных.
Но такой подход оставляет довольно большую ответственность в руках пользователя и, вероятно, не подходит для системы, которые ожидают действительно наивных пользователей, то есть людей, которые будут использовать систему только один, а может быть, два или три раза, поскольку требуется нетривиальный опыт, чтобы иметь возможность как знать, что нужно указать, так и
как это указать.
Другой способ подойти к проблеме персонализации – предоставить системе достаточно информации о пользователе, и что он может взять на себя ответственность за свою персонализацию. Это можно сделать тривиально или разумно. А тривиальный пример – это программа, которая просит пользователя оценить свой уровень знаний в системе. Затем программа использует
этот уровень, чтобы определить, какой объем информации следует предоставлять в сообщениях об ошибках. Программа по существу содержит модели того, сколько информации люди уже имеют на каждом уровне.
Во многих системах требуется более сложный подход к автоматическому моделированию пользователей, чтобы иметь дело с обоими потребность в дополнительной информации о каждом пользователе и проблема, заключающаяся в том, что пользователи не всегда могут сообщить системе, что ей нужно знать. Примеры этой последней проблемы часто встречаются в области автоматизированного обучения (CAI). А Система CAI должна знать, что каждый отдельный ученик знает, не знает или знает неправильно. Студент, к сожалению, не всегда знает то, чего не знает, а тем более то, что знает неправильно.
Конечно, не только студенты не знают себя. Есть много доказательств в психологической литературе, подтверждающие утверждение, что люди не являются надёжными источниками информации о самих себе [см., например, Nisbett & Wilson (1977) и McGuire & Padawer- Singer (1976)]. В добавок к отсутствие точности, присущее явным моделям, есть ещё одно соображение, которое приводит доводы в пользу разрешения системы
сам строит свои пользовательские модели. Люди не хотят останавливаться и отвечать на большое количество вопросов, прежде чем они смогут воздействовать на то, для чего они пытаются использовать систему. Это особенно верно для людей, которые намерены использовать систему только несколько раз и только на короткое время. Чтобы лучше обслуживать этих пользователей, система должна формировать начальную модель как можно и пусть пользователь сразу же приступит к использованию системы. Эта исходная модель может быть основана на известных характеристиках всего сообщества пользователей системы, независимо от дополнительной информации, уже имеющейся в системе, что содержит информацию о каждом отдельном пользователе (например, его должность) и набор фактов, характеризующих нового пользователя системы.
Когда человек взаимодействует с системой, он предоставляет ей дополнительную информацию о себе. Как он приобретает эту информацию, система может постепенно обновлять свою модель пользователя, пока в конечном итоге не станет моделью этого индивидуального пользователя в отличие от канонического пользователя. При таком подходе наибольшие усилия будут затрачены на построение моделей частых пользователей, при этом гораздо меньше усилий будет затрачено на модели крайне редких пользователи, модели, которые мало что дадут с точки зрения общей удовлетворённости пользователей.
Наиболее важный вывод из решения позволить системе построить свою собственную модель пользователя tJte, основанную на взаимодействия между ними заключается в том, что большая часть информации, содержащейся в модели, будет предполагаемой. Таким образом, система должен иметь какой-то способ представить, насколько он уверен в каждом факте, в дополнение к способу разрешения конфликтов и обновление модели по мере появления новой информации. В разделе 3 будет предложено несколько способов сделать это.
2.3. Долгосрочные и краткосрочные модели
Обсуждая первые два из этих трёх измерений, можно было утверждать, что одна из форм пользовательского моделирования может привести к более обитаемой системе, чем другая. При обсуждении этого третьего измерения это уже не так. Для того, чтобы обеспечить условия для разумного взаимодействия с пользователем система должна иметь доступ к широкому спектру информации о нем, начиная с от относительно долгосрочных фактов, таких как его уровень математической сложности, до довольно краткосрочных фактов, таких как тема последнего предложения, введённого пользователем. Хотя вся эта информация может способствовать обитаемости системы, полезно, по крайней мере, в начале исследования темы моделирования пользователей, разделить
проблема выведения (исключения) долгосрочных моделей из проблемы вывода краткосрочных моделей, потому что различные методы могут подходит для решения двух проблем.
Вероятно, разумно потребовать, чтобы количество усилий, затраченных на принятие решения по конкретному факту о пользователе, было примерно пропорционально количеству времени, в течение которого этот факт можно будет использовать. С одной стороны, важно, чтобы
не было больших затрат времени, чтобы можно было определить столько времени тратится на попытки сделать вывод о том, что этот факт больше не актуален. С другой стороны, может быть разумным потратить много времени на несколько сеансов, чтобы сформировать точную модель некоторых по сути постоянных характеристик.
Были предприняты усилия как для долгосрочного, так и для краткосрочного моделирования отдельных пользователей. Краткосрочное моделирование важно для понимания диалога на естественном языке. Рассмотрим, например, следующий обмен:
Покупатель: Сколько стоит билет до Нью-Йорка?
Клерк: Одна сотня долларов.
Заказчик: Когда следующий самолёт?
Клерк: Следующий самолёт полностью забронирован, но еще есть место на одном, отправляется в 8:04.
Покупатель: ОК, возьму билет.
Чтобы дать такой ответ, клерк должен был сослаться на модель текущей цели клиента, чтобы добраться до Нью-
Йорка. Было бы неуместно отвечать на вопрос буквально 6:53. Если компьютерные системы будут выполнять задачу клерка в этом примере, тогда они тоже должны будут уметь строить и использовать модели целей своих пользователей. Но модели таких вещей, как текущие цели, носят довольно краткосрочный характер использования. Тот же самый покупатель может появиться завтра, намереваясь встретиться с кем-нибудь из Нью-Йорка, и таким образом ожидать другого ответа. Таким образом, необходимо разработать чрезвычайно гибкие методы, чтобы воспринимать такие цели и замечать, когда они меняются. Для более подробного обсуждения такого рода проблем см. Perrault, Allen & Коэн (1978) и Манн, Мур и Левин (1977).
Но многие системы могут с пользой использовать большое количество гораздо более стабильных знаний о своих пользователях. Эти долгосрочные модели могут быть получены в ходе серии взаимодействий между системой и её пользователями. В этой модели может содержаться такая информация, как уровень знаний пользователя в компьютерных системах в целом, его опыт с этой системой, в частности, и его знакомство с основной областью задач системы. В дополнение к этому есть общие вещи, которые могут быть использованы в самых разных системах, и пользовательским моделям, используемым в конкретной системе часто необходимо будет содержать конкретную информацию, относящуюся к системе и её области задач. Например, в Библиотечной программе, что будет обсуждаться в разделе 4, каждая пользовательская модель содержит информацию о таких вещах, как предпочтение книг с динамичными сюжетами и степень толерантности к описаниям насилия.
2.4. ОБЗОР ПРОСТРАНСТВА
На рисунке 1 показаны восемь классов моделей пользователей, порождённых тремя дихотомиями, которые мы только что обсудили, а также
с несколькими примерами каждого. Остальная часть этого документа будет сосредоточена на нижнем правом углу.

РИС. 1. Пространство пользовательских моделей.
3. Некоторые методы построения пользовательских моделей
Обозначив как необходимость моделирования пользователей, так и подходы, которые могут быть к нему приняты, некоторые вопросы теперь можно представить как конкретные методы, которые можно использовать для такого моделирования. В этом разделе представлены различные техники которые будут обсуждаться :
- определение словаря и понятий, используемых пользователем.
- оценка откликов, которыми пользователь кажется удовлетворён.
- использование стереотипов для создания множества фактов из немногих.
Эти методы делятся на две широкие группы: методы вывода отдельных фактов на время и методы для одновременного вывода целых групп фактов. В следующих двух разделах обсуждаются эти два типа
техники.
3.1. УКАЗАНИЕ ИНДИВИДУАЛЬНЫХ ФАКТОВ
Один из самых простых способов получить информацию о пользователе – это посмотреть, как он использует систему. Кто-то, кто начинает сеанс с ряда расширенных команд, вероятно, эксперт. Кто-то, чьи первые попытки выполнить формы команды отклоняются системой, вероятно, что он новичок и нуждается в некоторой помощи. Простой способ реализовать моделирование пользователя на основе такого рода информации состоит в построении словаря системных команд, параметров и т.д. далее, и связать с каждым элементом указание того, какую информацию о пользователе предоставляет использование этого элемента.
Эта информация может относиться к разным параметрам, таким как опыт работы с системой и опыт работы с
основная задача. После получения эту информацию можно использовать для расшифровки ошибок пользователя и для создания сообщений с правильным уровнем описания.
Другой способ, которым пользователи предоставляют информацию о себе, – это шаблоны своих команд. Предположим, что пользователь запрашивает у системы конкретную информацию. Если он получит то, что хочет, он либо уйдёт, либо продолжит и после будет его следующий запрос. Но если он не получит то, что хочет, он, вероятно, попытается реструктурировать свой запрос в другой попытке чтобы получить то, что хотел. Эта попытка должна сигнализировать системе, что она не удовлетворила потребность пользователя с первого раза. И он не получил удовлетворяющий ответ.
Использование обоих этих методов можно проиллюстрировать кратким исследованием системы, которую мы в настоящее время используем: Building, интерактивное средство справки для системы форматирования документов, Scribe (Рейд, 1980). Пользователи этой системы могут задавать такие вопросы, как:
- Как я могу создать индекс?
- Почему поля такие широкие?
- В чем разница между командой itemize и enumerate?
Система хранит свои знания о Scribe в виде набора правил «условие-действие». В простейшей форме эти правила
содержат одну команду Scribe в качестве условия, а соответствующее действие описывает эффект, производимый командой. Однако способ работы большинства команд определяется текущими значениями некоторого количества внутренних системных переменных, поэтому они тоже должны быть упомянуты как часть условий и правил. Это часто означает, что
несколько правил, каждое с разными условиями, все описывают работу одной и той же команды Scribe. В описание работы системы в соответствии с этими правилами является иерархическим. Действия, указанные во многих правилах не являются примитивными действиями, такими как размещение персонажа в определённом месте на странице, а являются более высокоуровневыми действия, и часто задействуют другие команды Scribe, эффекты которых, в свою очередь, описываются дополнительными правилами. Действие
компонентов многих правил – это установка некоторой системной переменной, которая в дальнейшем повлияет на работу других правил.
Эта иерархическая организация информации в системе позволяет такой системе отвечать на вопросы на разных уровнях детализации. Так, например, если системе задают вопрос «почему», например «Почему такие широкие поля?”, она может ответить либо указанием условий, которые привели к срабатыванию определённого правила (например, «Значение lmarg равно 10, а значение rmarg – 10»), или она может вернуться через правила, чтобы определить, как эти условия могли сбыться. Подходящий уровень для ответа на конкретный вопрос – это функция уровня самого вопроса и уровня знаний пользователя, задавшего вопрос. Для того, чтобы иметь возможность выбрать правильный уровень, система поддерживает словарь, который содержит запись для каждой из вещей
которые могут встречаться в правилах – как действия, так и условия. С каждой записью связана информация, которая описывает, когда может быть уместно упомянуть связанную концепцию в объяснении. Например, каждое
понятие имеет рейтинг, который описывает, насколько профессиональным должен быть человек в Scribe, чтобы понять объяснение с точки зрения этого. Таким образом, многие внутренние системные переменные имеют очень высокие рейтинги, в то время как простой пользователь использует часто команды с рейтингами очень низкими. У каждой концепции также есть отдельный рейтинг, который описывает уровень сложности с компьютерными системами, необходимыми для понимания этого. Например, входные файлы Scribe представляют собой блочные структуры, а файлы Scribe их обработка следует стандартной модели блочной структуры. Программист, пусть даже начинающий, как пользователь, понимает объяснение в этих терминах, в то время как более опытный программист не может.
Всякий раз, когда справочная система пытается найти ответ на вопрос, она сначала находит правило (или правила), применимые к конкретной ситуации. Затем он смотрит на концепции, упомянутые в этих правилах, и сравнивает то, что ему о них известно, и что ему известно о пользователе, задавшем вопрос. Если уровни совпадают, немедленно генерируется ответ. Если они этого не делают, система цепляется через правила, перемещаясь вверх или вниз по иерархии, в зависимости от ситуации, пока находит объяснение на правильном уровне.
Конечно, этот метод предполагает, что в справочной системе есть модель уровня подготовки пользователя. Как
можно ли построить такую сложную модель? К счастью, тот же словарь понятий, который использовался при эксплуатации модели также может быть использован для её построения. Когда пользователь задаёт вопрос, он формулирует его в терминах наблюдаемых действий (например, как символы на странице), команды Scribe и параметры Scribe. Тогда справочная система соответственно адресует этому вопрос к своей базе правил в его попытке ответить на него. Для этого он ищет каждый элемент вопроса в своём словаре (который также служит указателем в правилах). Люди часто относятся к понятиям проще, чем в большинство сложных из них, что они понимают, но они не говорят о концепциях более сложных, чем те, которые они понимают. Так система может начать построение своих моделей нового пользователя, принимая значения, связанные с первыми концепциями, которые он упоминал. Если позже будут упомянуты более сложные концепции, модель уровня знаний пользователя может быть повышена.
Модель пользователя также может быть изменена, как было предложено выше, путём наблюдения за шаблонами вопросов пользователя.
Предположим, что система неверно оценивает уровень пользователя и отвечает на его первый вопрос, ссылаясь на системный параметр, который ничего не значит для пользователя. Следующий вопрос пользователя почти наверняка будет относиться к этому параметру в попытке
выяснить, что это значит. Когда система видит это, она может сделать вывод, что её модель неверна, а затем изменить её, когда она обнаруживает уровень объяснения, которым удовлетворён пользователь. Аналогично, если система недооценивает знания пользователя, она даст ему довольно общие, совсем общие ответы, и наверное он запросит более конкретную информацию, и затем система может обновить свою модель.
Такое моделирование пользователей очень просто реализовать. Это делает почти наверняка необоснованное предположение, что существует фиксированный порядок, в котором люди узнают что-то о системе. Хотя это предположение, вероятно, неверно, это совершенно не так неправильно. Альтернативный подход заключался бы в создании для каждого пользователя подробной модели того, что именно он знает. Такой подход необходим в системах CAI, которые должны контролировать учебные занятия с такими моделями [см., например, Self (1977)]. Но этот подход очень дорог, как с точки зрения времени, необходимого для создания модели и места, необходимое для их хранения, для большого количества пользователей. Отношения между пользователем и система гораздо более свободны в контексте справочной системы, чем в системе CAI. Пользователь сохраняет контроль над взаимодействием, и вместо использования в концентрированных сессиях для усвоения идей обычно используются справочные системы время от времени для решения конкретных проблем. Таким образом, потребность в точной модели знаний пользователя менее острая. Хотя, конечно, нет чёткой границы, которую можно провести между этими двумя типами систем, кажется, что что во многих ситуациях неполные пользовательские модели могут быть полезны для справочной системы.
3.2. Использование стереотипов для вывода множества вещей одновременно.
Методы, которые обсуждались до сих пор, позволяют системе делать выводы об отдельных фактах о пользователе. Но если пользовательская модель должна быть очень сложной, то возникает вопрос о том, как собрать всю необходимую информацию в разумные сроки времени. Возможно, у пользователя будет только несколько обменов с системой, поэтому моделирование пользователя, которое требует множества от взаимодействия для построения исходной модели будет иметь мало пользы. К счастью, во многих ситуациях можно наблюдать одну или небольшое количество фактов и из них вывести с достаточной степенью точности набор дополнительных фактов. Человеческие черты не распределяются в популяции полностью случайным образом. Скорее они часто встречаются группами. Эти
кластеры могут возникать по разным причинам, например, из-за наличия единственного фактора, который заставляет несколько черт присутствуют сразу, или наличие причинной цепи между самими чертами. Например, богатый человек вероятно, путешествовал больше, чем другой очень бедный человек.
Люди представляют такие знания о сопутствующих чертах характера в виде набора стереотипов. Хотя слово стереотип имеет много негативных ассоциаций, важно ограничить его использование здесь чисто описательными перечислениями набора признаков, которые часто встречаются вместе. С этой точки зрения стереотип – это просто способ охвата некоторых структур, существующих в мире вокруг нас. За последние пару десятилетий работы в искусственного интеллекта, мы пришли к пониманию масштаба знаний, необходимых для рассуждений о
Мире К счастью, мы также обнаружили, что это знание имеет большую структуру, которая, если она может быть
захвачено, значительно ограничивает то, что необходимо учитывать в любой момент. Например, события не происходят случайно. Вместо этого обычные шаблоны событий, такие как вход в ресторан, получение меню, заказ, есть и платить. Эти шаблоны событий привели к разработке сценариев (Schank & Abelson, 1977), которые оказались чрезвычайно полезными при создании программ для понимания описаний событий, например, в газетных статьях. Стереотипы обеспечивают аналогичную структуру информации о людях. Только поскольку сценарии полезны для рассуждений о событиях, необходимых для понимания газетных статей, стереотипы полезны для рассуждений о людях, необходимых для построения пользовательских моделей. В частности, они могут предоставить способ формирования правдоподобных выводов о ещё невидимых вещах на основе вещей, которые были наблюдаемы.
Стереотип представляет собой набор черт. Его можно представить как набор пар атрибут-значение. Мы будем
назыввть каждый такой атрибут гранью. Модель отдельного пользователя также может быть представлена в виде набора граней (фасетов), заполненных ценностями. Грани стереотипов, используемых системой, должны соответствовать аспектам пользовательских моделей, построенных системой. Например, одна из черт, которую может быть полезно рассмотреть, – это уровень опыта пользователя с конкретной системой. Таким образом, модели отдельных пользователей, а также соответствующие стереотипы будут содержать аспект «опыта», который может принимать значения, скажем, от 1 до 10.
Некоторые черты легко заметить. Они служат триггерами, вызывающими активацию всего стереотипа.
Поскольку наличие какой-либо черты может указывать только на определённый стереотип, а не на абсолютное свидетельство в его пользу, с каждым триггером связан рейтинг, который является приблизительной мерой вероятности того, что стереотип уместен, учитывая, что триггер соблюдён. Конечно, это не только взаимосвязь между триггерами и стереотипами, которые в лучшем случае наводят на размышления. Стереотип говорит только о том, что набор черт часто встречается вместе, а не о том, что они всегда так делают. Итак, с каждым аспектом стереотипа должен быть связан рейтинг, оценивающий вероятность проявления соответствующей черты с учетом уместности стереотипа.
Стереотипы представляют собой структуру черт. Часто существует дополнительная структура, которую можно зафиксировать представленим набора стереотипов в виде иерархии. Информация в общих стереотипах может использоваться, если только противоречивую информацию подсказывают более конкретные стереотипы. Самый общий стереотип, доступный системе может представлять модель канонического пользователя. Таким образом, даже без большого количества информации система, построенная на стереотипах, будет работать не хуже, чем модель, построенная на традиционной встроенной модели канонического пользователя.
Одна из наиболее важных проблем, которую необходимо решить в любой системе моделирования пользователей на основе выводов из поведение пользователя заключается в том, как обнаруживать и разрешать конфликты между выводами. Чтобы облегчить это, рейтинги привязаны как к триггерам, так и к каждому предсказанию (аспекту) каждого стереотипа. Кроме того, каждая грань индивидуальной модели пользователя должна содержать не только значений, но и оценку уверенности системы в этом значении (которое может быть используется для определения того, насколько значение должно влиять на производительность системы в целом) и список причин, по которым считается ценность. Этот список причин важен. Например, предположим, что стереотип активируется в результате наблюдаемых черт пользователя. Этот стереотип предсказывает ценность определённого аспекта, но системная модель пользователя уже содержит другое значение для этого аспекта. Если система вспомнила, откуда взялось это значение, то можно довольно легко разрешить конфликт, например, если более раннее значение было получено из
стереотипа более общего, чем тот, который только что активизировался.
Иногда несколько разных стереотипов могут предсказывать одно и то же значение, а не разные для аспекта. В этом случае уровень уверенности системы в прогнозе может быть выше, чем если бы только один источник где информация присутствовала бы. Поскольку стереотипы разумно предсказывают другие стереотипы и в частности, пары значений для прогнозирования стереотипов, приток новой информации может потребовать распространения изменений рейтинга во всей пользовательской модели. Точная степень эффективности продолжения такого распространения – это вопрос, который необходимо определить эмпирически.
Все эти методы комбинирования выводов, основанных на различных стереотипах, можно обобщить, чтобы сформировать основу для интеграции более широкого спектра источников знаний об отдельном пользователе. Как бы полезны стереотипы не были, позволяя довольно быстро совершать начальное построение модели пользователя, они не исключают необходимости в других видах информации, включая как ответы на прямые вопросы, так и другие косвенные методы, описанные выше в контексте помощника Scribe. Но однажды каждый элемент пользовательской модели сопровождается рейтингом и списком доказательства, подтверждающих что в это, легко добавить произвольные источники знаний. Новая информация, поддерживающая старые значения вызывает повышение рейтингов, присваиваемых значениям. Новая информация, которая противоречит старым ценностям, вызывает средство разрешения конфликтов для проверки достоверности конкурирующих голосов для получения столь же точной оценки правды, как и возможный. Ответам пользователя на прямые вопросы можно отдать приоритет перед простыми выводами, которым, в свою очередь, могут быть
отдан приоритет предсказания стереотипов.
До сих пор обсуждение использования стереотипов было общим и избегало ссылок на конкретные системы или домены задач. В следующем разделе описывается конкретная система, которая успешно использовала стереотипы для построения моделей своих пользователей, которые будут обсуждаться. Общие моменты, упомянутые в этом разделе, будут проиллюстрированы конкретными примерами.
4. Гранди: пример использования стереотипов.
Для проверки многих идей, изложенных выше, была создана пилотная система под названием Grundy (Гранди). Гранди программа, которая рекомендует романы, которые люди могут захотеть прочитать. Для этого он использует два набора данных:
- описания отдельных книг. Каждое описание представляет собой набор аспектов, заполненных соответствующими значениями.
- стереотипы, содержащие аспекты, относящиеся к книжному вкусу людей. С каждым стереотипом связан
сборник триггеров.
Кроме того, Гранди обладает некоторыми знаниями о каждом из аспектов, которые могут встречаться в стереотипах. Это знание используется, чтобы помочь разрешить конфликты между конкурирующими выводами, а также для отображения информации в пользователе модели к информации в книжных описаниях. Для более полного описания Гранди, чем представленное читать здесь здесь см. Rich (1979a, b).
Когда новый пользователь начинает разговор с Гранди, его или её просят сказать несколько слов, которые, по его мнению, дать хорошее самоописание. Гранди использует эти слова как триггеры для соответствующих стереотипов, и начинается построение своей модели пользователя. Обычно на этом этапе активируется несколько стереотипов и часто возникают конфликты среди их прогнозов, которые Гранди решает как можно лучше. Затем Гранди оценивает (используя комбинацию количества вещей, в которые он верит, и насколько сильно он им верит) достаточно ли информации для начала процесса, что бы рекомендовать книги. Если да, то Гранди идет вперед. Если этого не происходит, он просит пользователя сказать ещё несколько слов.
На рисунке 2 показаны два стереотипа, использованных Гранди. На рисунке 3 показано, как будет выглядеть модель пользователя Гранди, например, после того, как ему сказали имя пользователя (и вывели из него, что она женщина) и после специальной активации
ЖЕНСКИЕ, ФЕМИНИСТИЧЕСКИЕ И ИНТЕЛЛЕКТУАЛЬНЫЕ стереотипы. Каждый раз, когда Гранди активирует стереотип, он также активирует все обобщения этого стереотипа, поэтому стереотипы ОБРАЗОВАННЫЙ и ЛЮБОЙ (канонический модель пользователя) также были активированы. Обратите внимание, что каждый из стереотипов содержит только некоторые аспекты, что содержится в полной пользовательской модели. Это часто происходит, потому что многие стереотипы связаны только с одним (или, возможно, с несколькими) важные аспекты человека.
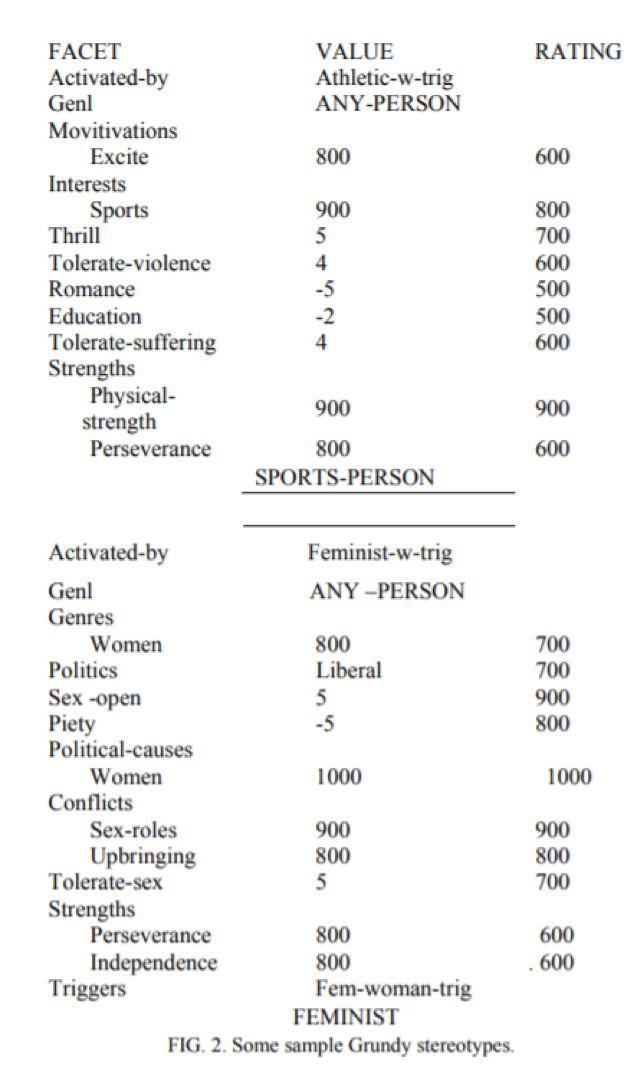
РИС. 2. Некоторые образцы стереотипов Гранди.
После того, как он накопит достаточно информации, чтобы начать работу, Гранди начинает рекомендовать книги по одной, пока пользователь говорит ему остановиться. Процесс выбора книги происходит следующим образом.
- Выберите заметный фасет в пользовательской модели. Существенными аспектами являются те, которые имеют не средние ценности и высокие рейтинги.
- Используйте перевёрнутый индекс в базе данных книг, чтобы выбрать все книги, предложенные этим конкретным значением аспекта.
- Сравните каждую из выбранных книг с моделью пользователя по всем параметрам. Исключите книги, превышающие определённые пороги (например, терпимость к насилию).
- Из книг, которые не были исключены, выберите ту, которая лучше всего подходит. Если он выше порога близости совпадения, Гранди рекомендует. В противном случае перейдите к шагу 1, выберите новый фасет и повторите попытку.
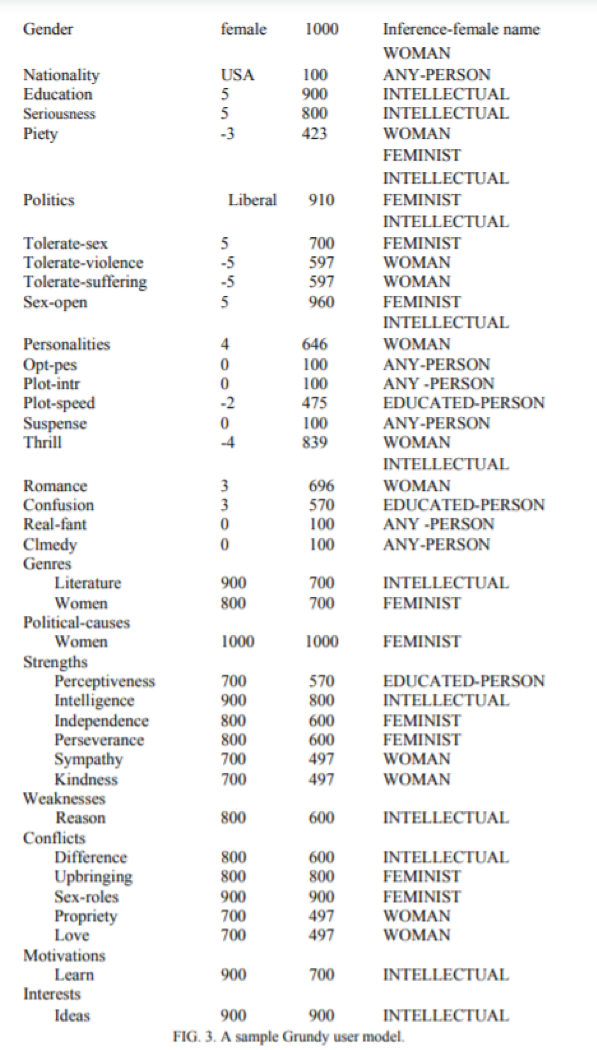
РИС. 3. Пример пользовательской модели Grundy.
Выбрав книгу, Гранди сообщает пользователю имя ее автора и название, а затем спрашивает пользователя, читал ли он это раньше. Если да, Гранди знает, что он на правильном пути. Теперь он может укрепить свою веру в то, что привело его к выбору этой книги. (См. Раздел 5 для более подробного обсуждения вопроса об изменении базы данных Гранди.) Если пользователю книга не понравилась, Гранди нужно выяснить, почему. В идеале было бы просто сказать: «Почему бы и нет?», Но гораздо больше потребуются знаний, чем у Гранди, для интерпретации ответов на такой вопрос . Например, кто-то может сказать, что книга ему не понравилась, потому что главный герой напомнил ей ее дантиста. Вместо этого Гранди пытается выяснить, какое из представлений о пользователе, которое он использовал при выборе этой книги, было неправильным. Для этого он
Задаёт несколько прямых вопросов, пока не обнаружит проблему или не откажется от неё. Если он обнаружил проблему, то он может обновлять как свою модель пользователя, так и свою базу стереотипов.
Если пользователь говорит Гранди, что она не читала книгу, Гранди сообщает ей некоторые вещи, которые, по его мнению, могут заинтересовать её. Гранди использует свою модель пользователя, чтобы выбрать, какие характеристики книги следует упомянуть. Затем он спрашивает. что пользователь думает, что книга ему может понравится. На этот раз, если она скажет «да», Гранди ничего не сделает, поскольку положительный ответ основан только на нескольких фактах, которые видел пользователь. Но если пользователь говорит, что книга не смотрится интересной, то Гранди использует описанную выше процедуру, чтобы попытаться выяснить, что пошло не так, чтобы он мог попытаться найти то, что ей больше понравится.
Чтобы проверить полезность пользовательских моделей Гранди, был проведён эксперимент, в котором Гранди дал каждому из пользователей столько предложений, сколько они хотели. Он также дал каждому из них несколько случайно выбранных предложений без помощи модели пользователя и спросил их, хорошо ли выглядят предложения. Они послужили контролем.
В таблице 1 показан процент предложений, которые были описаны как хорошие, по сравнению с предложениями, описанными как плохие в управляемом режиме (где выбор определяла модель пользователя) и в случайном режиме. Эти цифры показывают, что Гранди значительно (p <10-9) работает с пользовательской моделью лучше, чем без неё.
Хотя модели пользователей Гранди и близко не подходят к улавливанию всех сложно связанных факторов, которые
определяют, какие романы понравятся человеку, его успешность при внесении предложений указывает на то, что пользовательские модели могут служить полезным руководством для интерактивных систем.
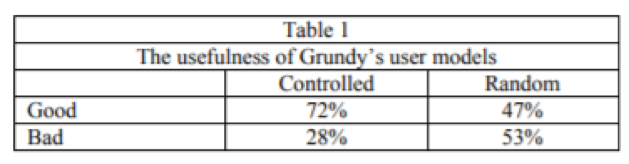
Таблица 1.
Полезность пользовательских моделей Гранди
5. Обучение в Гранди
Стереотипы чрезвычайно полезны, позволяя системе быстро построить начальную модель нового пользователя, чтобы она могла заниматься тем, что является настоящей задачей. Но как мы можем выработать точные стереотипы для использования в системе? Будут ли такое, что все попытки моделирования пользователей окажутся бесполезными, если стереотипы неверны? Это важные вопросы, которые все ещё требуют полных ответов, но опыт работы с Гранди показывает, что они не представляют собой непреодолимых препятствий.
Первоначальные стереотипы Гранди отражали лишь мои интуитивные представления о людях и книгах, которые они читают. Попытки не было сделано для сбора любых достоверных данных. Несмотря на это, стереотипы очень полезны. Но самое интересное, что может быть наблюдается, что Гранди способен изменять свои стереотипы на основе своего опыта, когда этот опыт
противоречит предсказаниям стереотипов. Возможны только довольно простые модификации. Фасеты не могут быть добавлены или удален, но значение фасета может измениться, как и его рейтинг.
Первоначальный стереотип Гранди о типичном читателе -мужчине указывал на то, что мужчины любят читать книги с динамичными сюжетами, и получать много острых ощущений и азарта. Это может относиться к мужскому населению США. Но мужчины Гранди
на самом деле, как мы видели, были не очень широкими слоями этого населения; все они были преподавателями и выпускниками университета, студентами. Поэтому им нравились интеллектуальные книги, которые больше касались философии, чем сюжета. Так Гранди постепенно изменил свой стереотип MAN, чтобы отразить вкусы людей, которых он действительно видел,чем какое-то население, которое я себе представляла. Тот факт, что он мог это сделать, предполагает две обнадеживающие вещи о достоинствах использования стереотипов в системах моделирования пользователей:
- наличие точных данных, описывающих сообщество пользователей, не критично для построения первоначального набора стереотипов.
- если одна система используется в различных сообществах, ее стереотипы могут развиваться отдельно в каждом из них, потому что каждый характеризуется довольно точно.
Конечно, возможны и другие типы обучения, которых Гранди не делает. Grundy хранит все свои пользовательские модели, потому что, когда пользователь возвращается для более поздних сеансов, новую модель не нужно строить с нуля. Таким образом можно было бы создавать совершенно новые стереотипы, наблюдая за образцами черт, которые обычно встречаются у пользователей.
6. Заключение
В этой статье я утверждала, что для многих интерактивных компьютерных систем сообщество пользователей достаточно неоднородно, что единственная модель канонического tiser неадекватна. Вместо этого представляется возможность формировать индивидуальные модели отдельных пользователей. А потом я показала, что такие модели, помимо необходимости, также возможны, и был представлен набор способов их создания и использования.
Все эти методы объединяет то, что они предполагают предположения о пользователе. Эти догадки
производится системой на основе её взаимодействия с пользователем. В результате возможность ошибки всегда должна быть просчитана. Чтобы справиться с этим, система должна делать две вещи:
- она должна давать оценки и обоснования каждому из своих убеждений.
- она не должна рассматривать модель пользователя как фиксированную, а скорее как нечто, что можно постоянно улучшать путем сбора отзывов пользователей о каждом взаимодействии.
Ссылки
КАРТА, С.К., МОРАН, Т.П. и НЬЮЭЛЛ, А. (1980). Модель уровня нажатия клавиш для оценки времени работы пользователя с интерактивными системами. Сообщения Ассоциации вычислительной техники, 23, 396-410.
CODD, EF (1974). Семь шагов к рандеву со случайным пользователем. В KLIMBIE, JW & KOFFEMAN, KL,
Редакторы, Управление базой данных. Амстердам: Северная Голландия.
КАФФ, Р. Н. (1980). На случайных пользователей. Международный журнал человеко-машинных исследований, 12, 163-187.
ФИТТС, П.М. и ПЕТЕРСОН, Дж. Р. (1964). Информационная емкость дискретных двигательных реакций. Журнал Экспериментальная психология, 67, 103-112.
ГЕНЕЗЕРЕТ М. (1978). Автоматизированный пользовательский консультант MACSYMA. Кандидат наук. докторская диссертация, Гарвардский университет.
ХАДЖЕНС, Джорджия, и БИЛЛИНГСЛИ, Пенсильвания (1978). Пол: недостающая переменная в исследовании человеческого фактора. Человеческие Факторы, 20, 245-250.
ЛЕДГАРД, Х., УАЙТЗИД, Дж. А., Сингер, А. и СЕЙМУР, В. (1980). Естественный язык интерактивных
системы. Сообщения Ассоциации вычислительной техники, 23, 556-563.
LOO, R (1978). Индивидуальные отличия и восприятие дорожных знаков. Человеческий фактор, 20, 65-74.
МАНН, У.С., Мур, Дж. А. и Левин, Дж. А. (1977). Модель понимания человеческого диалога. В
Труды Международной объединённой конференции по искусственному интеллекту, 5, 77-87.
МАКГУИР, У.Д. и ПАДАВЕР-ЗИНГЕР, А. (1976). Особенность спонтанной самооценки. Журнал
Личность и социальная психология, 33, 743-754.
МИТТМАН Б. и БОРМАН Л. (1975). Системы персонализированных баз данных. Лос-Анджелес: Melville Publishing Co.
НИСБЕТТ, Р. Э. и УИЛСОН, Т. Д. (1977). Рассказывать больше, чем мы можем знать: устные отчеты о психических процессах. Психологический обзор, 84, 231-259.
Перро, К. Р., Аллен, Д. Ф. и КОЭН, П. Р. (1978). Речь служит основой для понимания диалога согласованности. В материалах Второй конференции по теоретическим вопросам обработки естественного языка
РИД, Б.К. (1980). Scribe: язык спецификации документов и его компилятор. Кандидат наук. диссертация, Карнеги-Меллон Университет.
РИЧ, EA (1979a). Создание и использование пользовательских моделей. ‘Кандидат наук. защитил диссертацию в Университете Карнеги-Меллона.
РИЧ, EA (1979b). Моделирование пользователей с помощью стереотипов. Когнитивная наука, 3, 329-354.
РОБЕРТСОН, Г., НЬЮЭЛЛ, А., РАМАКРИШНА, К. (1981). Подход ZOG к человеку-машине
общение. Внутренний журнал исследований человека и машины, 14 (4), 461-488.
SCHANK, R. & ABELSbN, R. P. (1977). Цели, планы, сценарии и понимание: исследование человека
Структуры знаний. Хиллсдейл, Нью-Джерси: Erlbaum Press.
СЕЛФ, JA (1977). Концепция обучения. Искусственный интеллект, 9, 197-221.
СМИТ, С. (1979). Размер букв и удобочитаемость. Человеческий фактор, 21, 661-670.